聚合(Aggregations)也拥有一种可组合(Composable)的语法:独立的功能单元可以被混合在一起来满足你的需求。这意味着需要学习的基本概念虽然不多,但是它们的组合方式是几近无穷的。 聚合函数分为两个主要的类别:
- bucket(桶):满足某个条件的文档集合
- metrics(指标):为某个桶中的文档计算统计信息
一个多级聚合的示例:
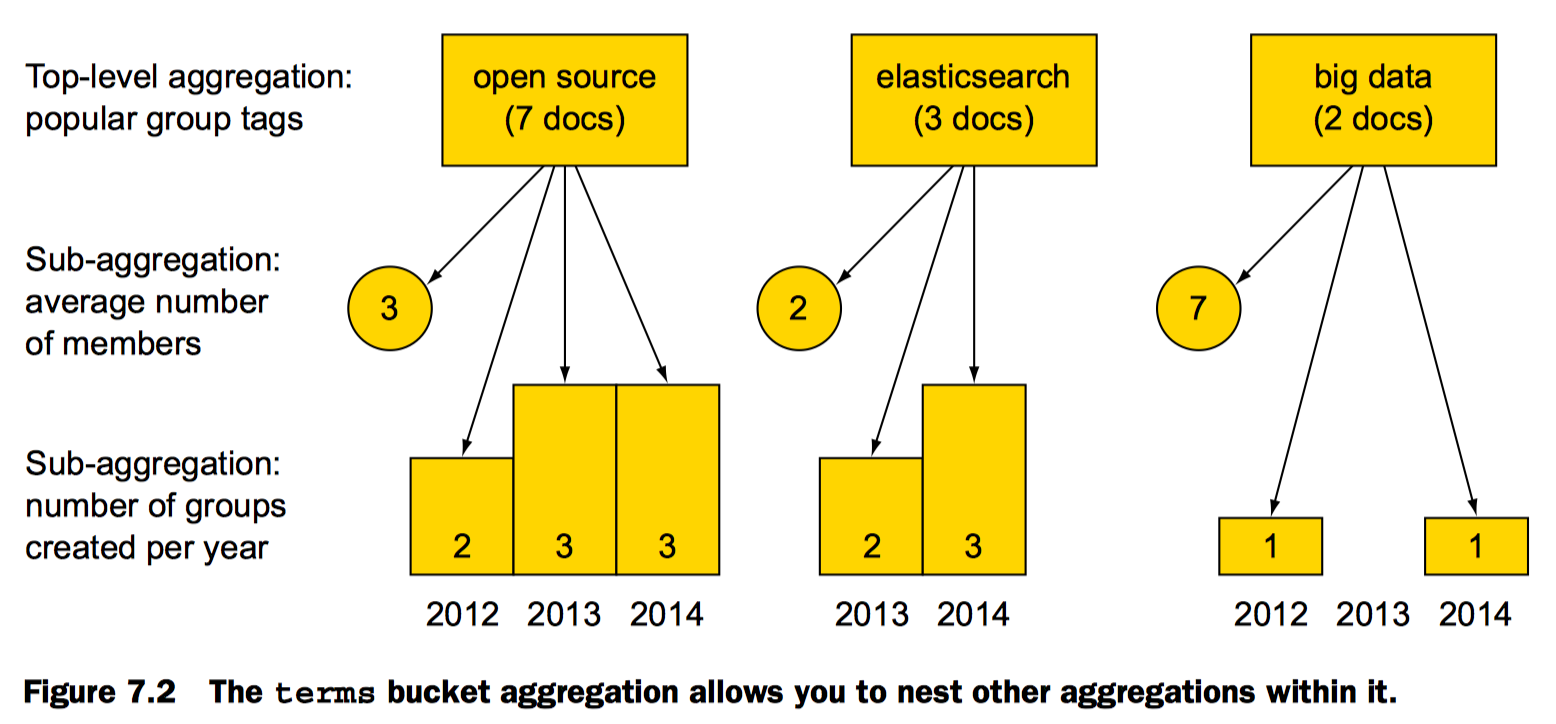
剖析聚合函数
- 在查询请求的json结构中添加聚合相关参数,参数的key是aggregations或者aggs。还需要为聚合定义一个名称,并设置聚合的type,以及其他相关参数。
- 聚合是基于查询结果执行的
- 进一步的过滤不会影响聚合
聚合请求的结构
示例:使用terms聚合获取热门tags
curl 'localhost:9200/get-together/group/_search?pretty' - d '{
//aggregations key表明这是请求中执行聚合的部分
"aggregations": {
//为该聚合取一个名称
"top_tags": {
//指定聚合的类型
"terms": {
//not_analyzed verbatim字段便于精确统计
"field": "tags.verbatim"
}
}
}
}
'
//返回结果
[...]
"hits" : {
"total" : 5,
"max_score" : 1.0,
"hits" : [ {
[...]
"name": "Denver Clojure",
[...]
"name": "Elasticsearch Denver",
[...]
},
"aggregations" : {
"top_tags" : {
"buckets" : [
{ "key" : "big data", "doc_count" : 3 },
{ "key" : "open source", "doc_count" : 3 },
{ "key" : "denver", "doc_count" : 2
[...]
}
}
注:
- aggregations可简写为aggs
- 为aggregations取的名称再返回结果中可以看到。这在多个聚合时会很好分辨聚合对应的结果。
- 设定了聚合的类型为terms还有就是聚合的用到的文档参数
- 不设置query默认查询所有
基于查询结果执行聚合
示例:groups的文档中location字段为Denver的热门tag
curl 'localhost:9200/get-together/group/_search?pretty' -d '{
"query": {
"match": { "location": "Denver" }
},
"aggregations" : {
"top_tags" : {
"terms" : { "field" : "tags.verbatim" }
}
}
}'
//返回结果
[...]
"hits" : {
"total" : 2,
"max_score" : 1.44856,
"hits" : [ {
[...]
"name": "Denver Clojure",
[...]
"name": "Elasticsearch Denver",
[...]
},
"aggregations" : {
"top_tags" : {
"buckets" : [
{ "key" : "denver", "doc_count" : 2 },
{ "key" : "big data", "doc_count" : 1
[...]
过滤和聚合
一般的filter
一般的filter和query类似,聚合都是基于过滤出的结果执行的。
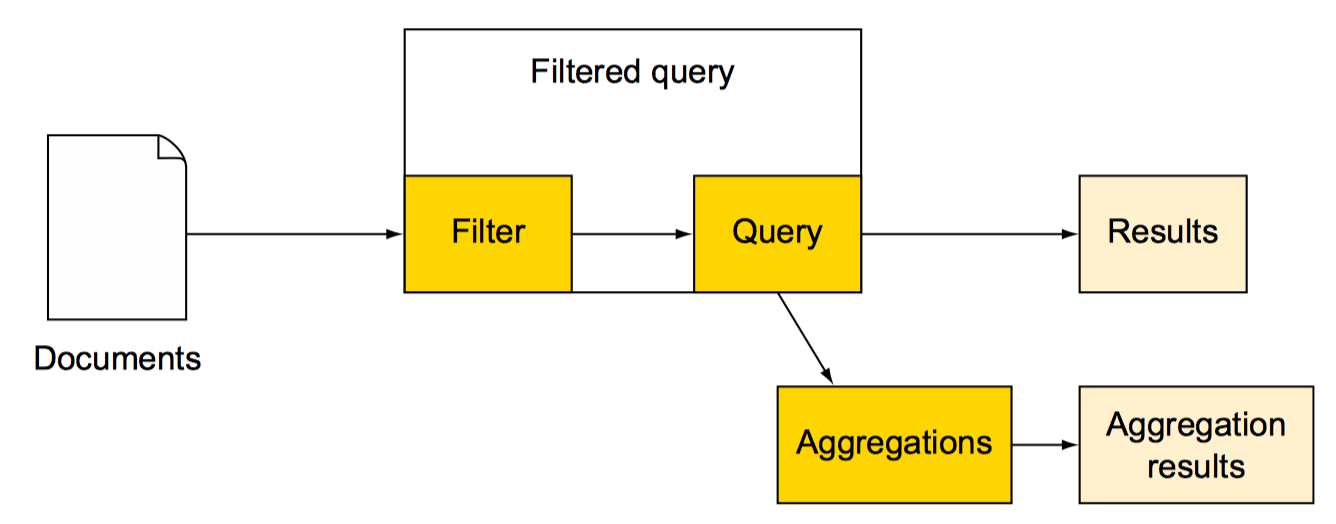
后置过滤:post_filter
先执行query,过滤和聚合都是基于query结果执行的。也就是filter更改不会影响聚合结果
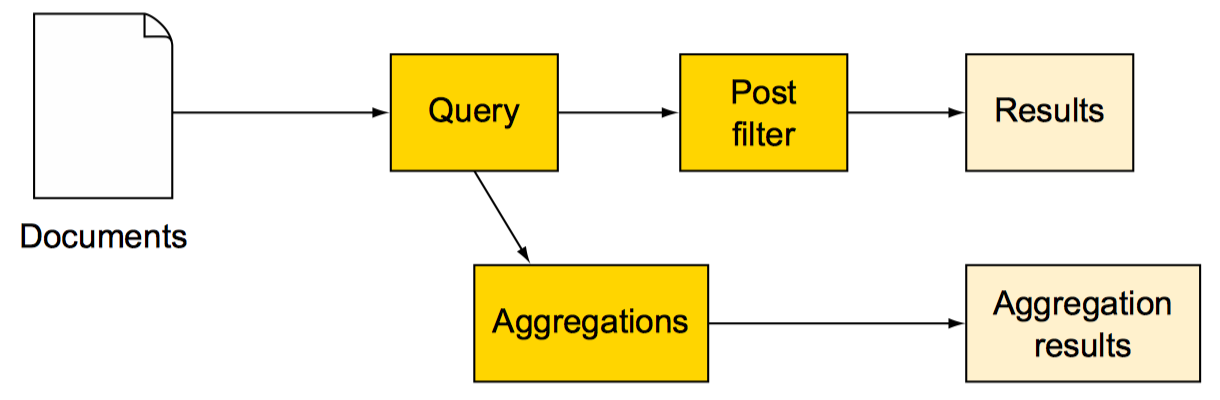
- post_filter性能不及一般filter
- post_filter中过滤和聚合是相互独立的
Metrics aggregations (指标性质的聚合函数)
桶(bucket)能够让我们对文档进行有意义的划分,但是最终我们还是需要对每个桶中的文档进行某种指标计算。多数指标仅仅是简单的数学运算(比如,min,mean,max以及sum),它们使用文档中的值进行计算。在实际应用中,指标能够让你计算例如平均薪资,最高出售价格,或者百分之95的查询延迟。
Statistics (统计)
query时执行脚本性能不高(原因是要遍历所有相关文档),为了避免这个性能问题可以在index时将相关数据存入独立的字段中。
示例:获取attendees字段值的统计信息(attendees的值为数组)(聚合类型设置为stats,获取全部统计结果)
URI=localhost:9200/get-together/event/_search
//不关心搜索结果只要聚合结果,再次随便设置返回结果为search_type=count
curl "$URI?pretty&search_type=count" -d '{
"aggregations": {
"attendees_stats": {
"stats": {
"script": "doc['"'attendees'"'].values.length"
}
}
}
}'
//reply
[...]
"aggregations" : {
"attendees_stats" : {
"count" : 15,
"min" : 3.0,
"max" : 5.0,
"avg" : 3.8666666666666667,
"sum" : 58.0
}
}
}
获取单一统计结果比如平均值(统计类型设置为avg)
URI=localhost:9200/get-together/event/_search
curl "$URI?pretty&search_type=count" -d '{
"aggregations": {
"attendees_avg": {
"avg": {
"script": "doc['"'attendees'"'].values.length"
}
}
}
}'
//reply
[...]
"aggregations" : {
"attendees_avg" : {
"value" : 3.8666666666666667
}
}
}
和获取平均值类似,你也可以设置相应的聚合类型比如min, max, sum和value_count以获取相应的聚合结果
Advanced statistics(高级统计)
除了stats聚合获取的统计信息,extended_stats聚合还能获得平方和、方差、标准差等统计信息
示例:获取扩展统计信息
URI=localhost:9200/get-together/event/_search
curl "$URI?pretty&search_type=count" -d '{
"aggregations": {
"attendees_extended_stats": {
"extended_stats": {
"script": "doc['"'attendees'"'].values.length"
}
}
}
}'
### reply
"aggregations" : {
"attendees_extended_stats" : {
"count" : 15,
"min" : 3.0,
"max" : 5.0,
"avg" : 3.8666666666666667,
"sum" : 58.0,
//平方和
"sum_of_squares" : 230.0,
//方差
"variance" : 0.38222222222222135,
//标准差
"std_deviation" : 0.6182412330330462
}
}
Approximate statistics(粗略统计)
百分位统计(percentiles) 示例1:统计网站首页加载耗时百分比分布,以及平均加载耗时
GET /website/logs/_search
{
"size" : 0,
"aggs" : {
"load_times" : {
"percentiles" : {
"field" : "latency" #1
}
},
"avg_load_time" : {
"avg" : {
"field" : "latency" #2
}
}
}
}
//返回结果
...
"aggregations": {
"load_times": {
"values": {
//1%的用户会在75.55毫秒内加载完成
"1.0": 75.55,
"5.0": 77.75,
"25.0": 94.75,
"50.0": 101,
//75%的用户会在289.75毫秒内加载完成
"75.0": 289.75,
"95.0": 489.34999999999985,
//99%的用户会在596.2700000000002毫秒内加载完成
"99.0": 596.2700000000002
}
},
"avg_load_time": {
//用户加载平均耗时199.58333333333334毫秒
"value": 199.58333333333334
}
}
默认percentiles会返回一组预定义的百分位数值:[1, 5, 25, 50, 75, 95, 99]
示例2: 自定义返回的百分位数,如上例获取50%和99%的用户加载首页的耗时情况
GET /website/logs/_search
{
"size" : 0,
"aggs" : {
"load_times" : {
"percentiles" : {
"field" : "latency",
"percents" : [50, 99.0]
}
}
}
}
//返回结果
...
"aggregations": {
"load_times": {
"values": {
//50%的用户会在101毫秒内加载完成
"50.0": 101,
//99%的用户会在596.2700000000002毫秒内加载完成
"99.0": 596.2700000000002
}
}
}
百分位等级统计(percentile_ranks) 简单解释就是某些数值的百分比占位。还是上面首页加载的例子,210毫秒以内完成加载的用户占比,800毫秒以内完成加载的用户占比
示例:分区域统计分别统计210毫秒以内和800毫秒以内完成首页加载的用户占比
GET /website/logs/_search
{
"size" : 0,
"aggs" : {
"zones" : {
"terms" : {
"field" : "zone"
},
"aggs" : {
"load_times" : {
"percentile_ranks" : {
"field" : "latency",
"values" : [210, 800]
}
}
}
}
}
}
//返回结果
"aggregations": {
"zones": {
"buckets": [
{
"key": "eu",
"doc_count": 6,
"load_times": {
"values": {
//eu这个地方210毫秒以内加载完成的用户约占32%
"210.0": 31.944444444444443,
"800.0": 100
}
}
},
{
"key": "us",
"doc_count": 6,
"load_times": {
"values": {
//us这个地方210毫秒以内加载完成的用户占比100%
"210.0": 100,
"800.0": 100
}
}
}
]
}
}
percentiles和percentile_ranks一个以百分数作为key统计值,一个以值为key计算百分数
基数统计(cardinality) 返回字段的唯一值的数目,示例:我们可以用基数度量确定经销商销售汽车颜色的种类
GET /cars/transactions/_search
{
"size" : 0,
"aggs" : {
"distinct_colors" : {
"cardinality" : {
"field" : "color"
}
}
}
}
//返回结果:在售车有三种颜色
...
"aggregations": {
"distinct_colors": {
"value": 3
}
}
...
cardinality有些类似于SQL的distinct
基于性能和精度的问题,我们需要权衡,因此引入了参数precision_threshold阀值定义了在何种基数(cardinality)水平下我们希望得到一个近乎精确的结果。
GET /cars/transactions/_search
{
"size" : 0,
"aggs" : {
"distinct_colors" : {
"cardinality" : {
"field" : "color",
"precision_threshold" : 100
}
}
}
}
precision_threshold 接受 0–40,000 之间的数字,更大的值还是会被当作 40,000 来处理。
示例会确保当字段唯一值在100以内时会得到非常准确的结果。尽管算法是无法保证这点的,但如果基数在阀值以下,几乎总是 100% 正确的。高于阀值的基数会开始节省内存而牺牲准确度,同时也会对度量结果带入误差。
对于指定的阀值,HLL 的数据结构会大概使用内存 precision_threshold * 8 字节,所以就必须在牺牲内存和获得额外的准确度间做平衡。
在实际应用中,100 的阀值可以在唯一值为百万的情况下仍然将误差维持 5% 以内。
感谢:http://www.cnblogs.com/richaaaard/p/5319299.html
指标(Metrics)聚合和典型用例
| Aggregation type | 用例 |
|---|---|
| stats | 一次返回多种统计信息,如最大值,最小值,求和,平均值,值的数量 |
| individual stats (min, max, sum, avg, value_count) | 最大值,最小值,求和,平均值,值的数量 |
| extended_stats | 平方和,方差,标准差 |
| percentiles | 首页加载的百分比分布 |
| percentile_ranks | 统计100ms以内完成首页加载的百分比 |
| cardinality | 统计访问站点的独立IP数目 |
分类聚合(Multi-bucket aggregations)
分类聚合具体包含如下详细分类:
- Terms aggregations
- Range aggregations(范围聚合)
- Histogram aggregations(直方图聚合)
- Nested, reverse nested, and children aggregations(蜂窝聚合,逆蜂窝聚合以及子聚合,第八章会讲到)
- Geo distance and geohash grid aggregations(地理距离聚合 和 地理方格聚合 附录A会讲到)
Terms聚合
通常的使用场景之一就是统计term的出现频率,不是某个字段值得出现频率。使用在non-analyzed字段这个字段值就可作为一个term。也可用在analyzed字段,可利用这一点制作高频词汇的标签云。
返回结果排序(order) 默认统计结果按term数量的降序(desc)排列,也可以自定义排序方式 示例:根据tag值,升序排列(也就是字母表升序排列(a -> z))
URI=localhost:9200/get-together/group/_search
curl "$URI?pretty&search_type=count" -d '{
"aggregations": {
"tags": {
"terms": {
"field": "tags.verbatim",
"order": {
"_term": "asc"
}
}
}
}
}'
//返回结果
"aggregations" : {
"tags" : {
"buckets" : [
{ "key" : "apache lucene", "doc_count" : 1 },
{ "key" : "big data", "doc_count" : 3 },
{ "key" : "clojure", "doc_count" : 1
返回结果的不确定性
默认terms聚合根据预定义的排序规则返回top 10记录。
可以设置参数size修改返回记录的数目.当size设置为0时,会全部返回。这样做是不推荐的,非常危险数据量大时会导致ES崩溃。
使用terms聚合,结果可能带有一定的偏差与错误性。
举个例子: 我们想要获取name字段中出现频率最高的前5个。
理想情况描述:
此时,客户端向ES发送聚合请求,主节点接收到请求后,会向每个独立的分片发送该请求。 分片独立的计算自己分片上的前5个name,然后返回。当所有的分片结果都返回后,在主节点进行结果的合并,再求出频率最高的前5个,返回给客户端。
一般情况:
这样就会造成一定的误差,比如最后返回的前5个中,有一个叫A的,有50个文档;B有49。但是由于每个分片独立的保存信息,信息的分布也是不确定的。有可能第一个分片中B的信息有2个,但是没有排到前5,所以没有在最后合并的结果中出现。这就导致B的总数少计算了2,本来可能排到第一位,却排到了A的后面。
解决办法: 使用size和shard_size参数。
- size参数规定最终返回的term个数(默认是10个)
- shard_size参数规定在每个分片上执行时返回的term个数
- 如果shard_size小于size,那么分片也会按照size指定的个数计算
通过这两个参数,如果我们想要返回前5个,size=5;shard_size可以设置大于5,这样每个分片返回的词条信息就会增多,相应的误差几率也会减小。
min_doc_count与shard_min_doc_count
聚合的字段可能存在一些频率很低的term,如果这些term数目比例很大,那么就会造成很多不必要的计算。 因此可以通过设置min_doc_count和shard_min_doc_count来规定最小的文档数目,只有满足这个参数要求的个数的term才会被记录返回。
通过名字就可以看出:
- min_doc_count:规定了最终结果中term关联文档的最小数目
- shard_min_doc_count:规定了分片计算中term关联文档的最小数目
通配符匹配创建bucket聚合 include可以过滤出包含该值的文档;相反则使用exclude
示例:结果应该包含sport并且不包含water。
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"include" : ".*sport.*",
"exclude" : "water_.*"
}
}
}
}
数组匹配创建bucket聚合
示例:定义包含与排除的信息
{
"aggs" : {
"JapaneseCars" : {
"terms" : {
"field" : "make",
"include" : ["mazda", "honda"]
}
},
"ActiveCarManufacturers" : {
"terms" : {
"field" : "make",
"exclude" : ["rover", "jensen"]
}
}
}
}
collect模式 对于子聚合的计算,有两种方式:
- depth_first 直接进行子聚合的计算
- breadth_first 先计算出当前聚合的结果,针对这个结果在对子聚合进行计算。
默认情况下ES会使用深度优先,不过可以手动设置成广度优先
{
"aggs": {
"actors": {
"terms": {
"field": "actors",
"size": 10,
"collect_mode": "breadth_first"
},
"aggs": {
"costars": {
"terms": {
"field": "actors",
"size": 5
}
}
}
}
}
}
感谢:http://www.cnblogs.com/xing901022/p/4947436.html
significant_terms 显著项 分析数据,找出那些与大量背景数据相比出现频率统计异常的项。 统计出与异常概率事件相关的事件。这个东西就类似于机器学习。 大数据背景下的小概率事件, 特定样本背景下的大概率事件
关键理解资料:http://www.cnblogs.com/richaaaard/p/5328948.html
基于受欢迎度推荐(Recommending Based on Popularity) 我们可以采取的首个策略就是基于受欢迎度向用户推荐影片。对于某部影片,我们可以找到所有推荐过它的用户,然后我们可以将他们推荐的影片进行聚合并获得推荐中最受欢迎的五部。
基于统计的推荐(Recommending Based on Statistics) 现在场景已经设定好,让我们使用 significant_terms 。 significant_terms 会分析喜欢影片 Talladega Nights 的用户组(前端用户组),并且确定最受欢迎的电影,然后为每个用户(后端用户)构造一个流行影片列表,最后将两者进行比较。 统计异常就是与统计背景相比在前景特征组中过度展现的那些影片。理论上讲,它应该是一组喜剧,因为喜欢 Will Ferrell 喜剧的人给这些影片的评分会比一般人高。
示例:找出和lee兴趣相投的人
GET /get-together/event/_search
{
"size": 0,
"query": {
"match": {
"attendees": "lee"
}
},
"aggs": {
"significant_attendees": {
"significant_terms": {
"field": "attendees",
// 滤除低频event
"min_doc_count": 2
}
}
}
}
//返回结果
...
"aggregations": {
"significant_attendees": {
"doc_count": 5,
"buckets": [
//lee一共参加了5个events
{
"key": "lee",
"doc_count": 5,
"score": 3,
"bg_count": 5
},
//greg一共参加了3个event,全部都是lee的
{
"key": "greg",
"doc_count": 3,
"score": 1.7999999999999998,
"bg_count": 3
},
//mike一共参加了2个event,全部都是lee的
{
"key": "mike",
"doc_count": 2,
"score": 1.2000000000000002,
"bg_count": 2
},
//daniel一共参加了3个event,只有2个和lee相同
{
"key": "daniel",
"doc_count": 2,
"score": 0.6666666666666667,
"bg_count": 3
}
]
}
}
//综上结果可知,返回了和lee兴趣相投的结果列表
terms: 返回和lee有共同兴趣的人,但不能反应出兴趣相投爱好一致
GET /get-together/event/_search
{
"size": 0,
"query": {
"match": {
"attendees": "lee"
}
},
"aggs": {
"terms_attendees": {
"terms": {
"field": "attendees",
"min_doc_count": 2
}
}
}
}
//返回结果
...
"aggregations": {
"terms_attendees": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "lee",
"doc_count": 5
},
{
"key": "greg",
"doc_count": 3
},
{
"key": "daniel",
"doc_count": 2
},
{
"key": "mike",
"doc_count": 2
}
]
}
}
//只反映出和lee有共同兴趣的人
//mike就参加了2个event 和 daniel 参加了三个event 他们都是和lee 有2个共同兴趣。很显然mike和lee的兴趣更趋近
terms 只是简单的聚合统计排序
significant_terms 是基于共同部分的统计排序,能反映出相关的程度
Range aggregations (区间聚合)
区间范围是上开下闭的 也就是大于等于A而小于B (A <= x < B) 区间范围不一定是独立的,也可以是重叠的比如2~6 和5~7就有重叠部分,只是不常用。见示例。
数值区间聚合
示例:分别统计events小于4个成员,至少4个成员小于6个成员,以及至少6个成员
GET /get-together/event/_search
{
"size": 0,
"aggs": {
"attendees_breakdown": {
"range": {
"script": "doc['attendees'].values.size()",
"ranges": [
{ "to": 4 },
{
"from": 4,
"to": 6
},
{
"from": 6
}
]
}
}
}
}
//返回结果:
...
"aggregations": {
"attendees_breakdown": {
"buckets": [
{
"key": "*-4.0",
"to": 4,
"to_as_string": "4.0",
"doc_count": 4
},
{
"key": "4.0-6.0",
"from": 4,
"from_as_string": "4.0",
"to": 6,
"to_as_string": "6.0",
"doc_count": 11
},
{
"key": "6.0-*",
"from": 6,
"from_as_string": "6.0",
"doc_count": 0
}
]
}
}
}
日期区间聚合(date_range) 示例:以2013.07为时间节点划分数据
GET /get-together/event/_search
{
"size": 0,
"aggs": {
"dates_breakdown":{
"date_range":{
"field": "date",
"format": "YYYY-MM",
"ranges":[
{"to": "2013-07"},
{"from": "2013-07"}
]
}
}
}
}
//返回结果
"aggregations": {
"dates_breakdown": {
"buckets": [
{
"key": "*-2013-07",
"to": 1372636800000,
"to_as_string": "2013-07",
"doc_count": 8
},
{
"key": "2013-07-*",
"from": 1372636800000,
"from_as_string": "2013-07",
"doc_count": 7
}
]
}
}
}
DateFormat: http:// joda-time.sourceforge.net/apidocs/org/joda/time/format/DateTimeFormat.html
更多用例参见:http://www.cnblogs.com/xing901022/p/4960451.html
Histogram aggregations(直方图聚合)
自定义固定的间隔,elasticsearch运算出range结果。比如自定义间隔是月,也就是每月,那么elasticsearch以月为区间间隔统计数据。区间边界和range聚合是一样的:左闭右开区间
histogram aggregations (直方图聚合) 示例:不同数量出席人员,出席的events. 比如有3个人出席的events有多少,有4个人出席的events有多少等等
GET /get-together/event/_search
{
"size": 0,
"aggs": {
"attendees_histogram": {
"histogram": {
"script": "doc['attendees'].values.size()",
"interval": 1
}
}
}
}
//返回结果
...
"aggregations": {
"attendees_histogram": {
"buckets": [
{
"key": 3,
"doc_count": 4
},
{
"key": 4,
"doc_count": 9
},
{
"key": 5,
"doc_count": 2
}
]
}
}
}
//有3个出席者的有4个events,有4个出席者的有9个events,//有5个出席者的有2个events
date_histogram(日期直方图聚合) 示例:每月发生的events数目
GET /get-together/event/_search
{
"size": 0,
"aggs": {
"event_dates": {
"date_histogram": {
"field": "date",
"interval": "1M"
}
}
}
}
//返回以月为时间间隔的数据集
"aggregations": {
"event_dates": {
"buckets": [
{
"key_as_string": "2013-02-01T00:00",
"key": 1359676800000,
"doc_count": 1
},
{
"key_as_string": "2013-03-01T00:00",
"key": 1362096000000,
"doc_count": 1
},
...
更多示例:http://blog.csdn.net/dm_vincent/article/details/42594043
多桶聚合以及典型用例
| Aggregation type | 用例 |
|---|---|
| terms | 根据term聚合排序,比如热门标签 |
| significant_terms | 趋势统计,基于统计的统计 |
| range and date_range | 区间范围统计,包括日期区间 |
| histogram and date_histogram | 直方图聚合,比如每月的销售额 |
Nesting aggregations (嵌套聚合)
组合不同聚合函数完成特定目的,才是最强大的。
示例:在terms聚合中嵌套date_histogram聚合
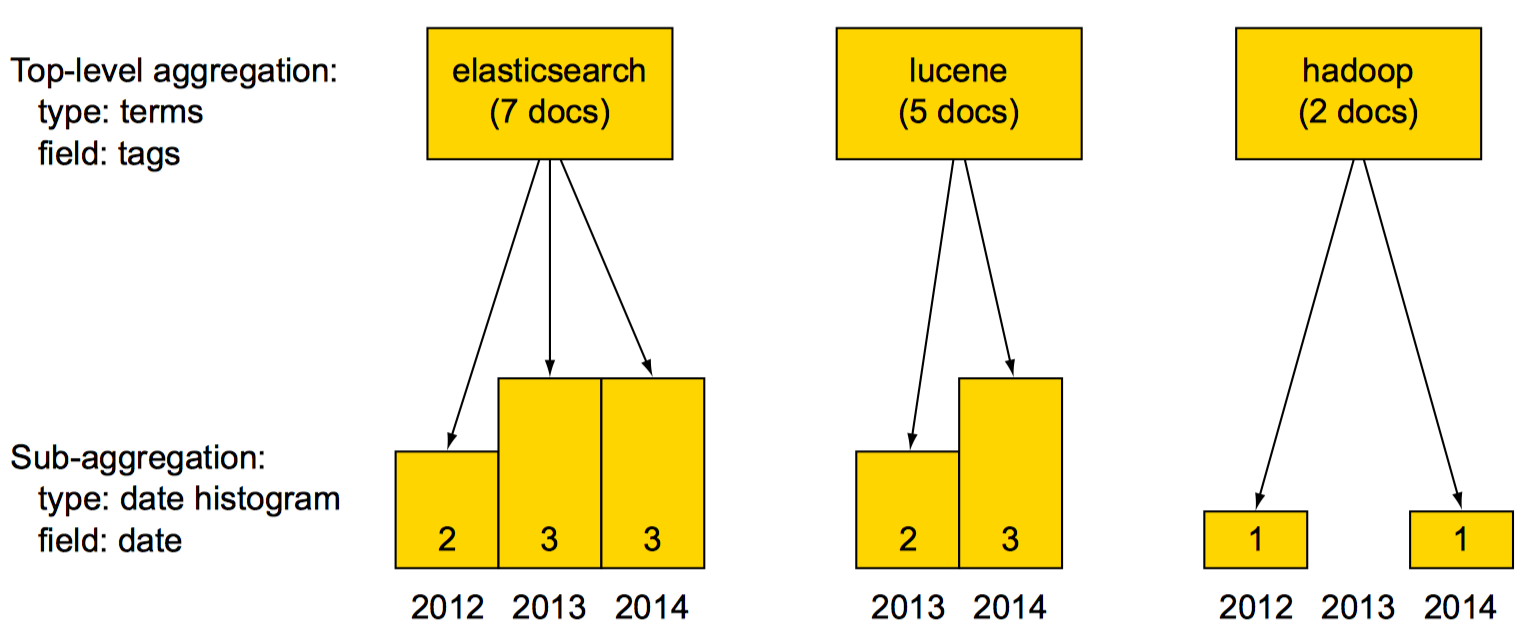
Nesting multi-bucket aggregations (嵌套多桶聚合)
示例:使用terms聚合统计热门tag, 使用date_histogram聚合统计每个热门tag每月新建的group数目,最后再使用range聚合统计有多少group有不到三个成员,有多少group至少有三个成员
GET /get-together/group/_search
{
"size": 0,
"aggs": {
"top_tags": {
"terms": {
"field": "tags.verbatim"
},
"aggs": {
"groups_per_month": {
"date_histogram": {
"field": "created_on",
"interval": "1M"
},
"aggs": {
"number_of_members": {
"range": {
"script": "doc['members'].values.size()",
"ranges": [
{ "to": 3 },
{ "from": 3 }
]
}
}
}
}
}
}
}
}
//返回结果
...
"aggregations": {
"top_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 6,
"buckets": [
{
//热门tag: big data 有三个文档
"key": "big data",
"doc_count": 3,
"groups_per_month": {
"buckets": [
{
//其中一个文档于2010年四月创建
"key_as_string": "2010-04-01",
"key": 1270080000000,
"doc_count": 1,
"number_of_members": {
//不足三个成员的文档有1个,多于三个成员的文档没有
"buckets": [
{
"key": "*-3.0",
"to": 3,
"to_as_string": "3.0",
"doc_count": 1
},
{
"key": "3.0-*",
"from": 3,
"from_as_string": "3.0",
"doc_count": 0
}
]
}
},
{
"key_as_string": "2010-05-01",
"key": 1272672000000,
"doc_count": 0,
"number_of_members": {
"buckets": [
{
"key": "*-3.0",
"to": 3,
"to_as_string": "3.0",
"doc_count": 0
},
{
"key": "3.0-*",
"from": 3,
"from_as_string": "3.0",
"doc_count": 0
}
]
}
},
...
Nesting aggregations to get result grouping(嵌套聚合获取结果分组)
示例:找到兴趣最广泛的top 2,获取他们最近参加的event
GET /get-together/event/_search
{
"size": 0,
"aggs": {
"frequent_attendees": {
"terms": {
"field": "attendees",
"size": 2
},
"aggs": {
"recent_events": {
"top_hits": {
"sort": {
"date": "asc"
},
"_source": {
"include": ["title"]
},
"size": 2
}
}
}
}
}
}
//返回结果
···
"aggregations": {
"frequent_attendees": {
"doc_count_error_upper_bound": 2,
"sum_other_doc_count": 50,
"buckets": [
{
"key": "lee",
"doc_count": 5,
"recent_events": {
"hits": {
"total": 5,
"max_score": null,
"hits": [
{
...
"_parent": "1",
"_source": {"title": "Liberator and Immutant"},
"sort": [1378404000000]
}
]
}
}
},
{
"key": "andy",
"doc_count": 3,
"recent_events": {
"hits": {
"total": 3,
"max_score": null,
"hits": [
{
...
"_parent": "4",
"_source": {"title": "Big Data and the cloud at Microsoft"},
"sort": [1375293600000]
}
]
}
}
}
]
}
}
}
Using single-bucket aggregations (单桶聚合)
Global (全局桶) 全局桶会包含你的所有文档,无论查询作用域是什么; 它完全绕开了作用域。由于它是一个桶,你仍然可以在其中嵌入聚合
示例:你想要知道Ford车相较所有车的平均价格。我们可以使用一个通常的聚合(作用域和查询相同)来得到Ford车的平均价格。而所有车的平均价格则可以通过全局桶来得到。
GET /cars/transactions/_search
{
"size" : 0,
"query" : {
"match" : {
"make" : "ford"
}
},
"aggs" : {
"single_avg_price": {
"avg" : { "field" : "price" }
},
"all": {
"global" : {},
"aggs" : {
"avg_price": {
"avg" : { "field" : "price" }
}
}
}
}
}
//返回结果
...
"hits": {
"total": 2,
"max_score": 0,
"hits": []
},
"aggregations": {
"all": {
"doc_count": 8,
"avg_price": {
"value": 26500
}
},
"single_avg_price": {
"value": 27500
}
}
}
感谢:http://blog.csdn.net/dm_vincent/article/details/42695339
Filter桶 过滤是聚合作用域的一个很自然的扩展。因为聚合工作在查询作用域的上下文中,那么适用于查询的任何过滤器也同样能够适用于聚合。
- filtered查询聚合示例:
使用filtered查询和使用match查询并无区别,该查询或过滤返回文档的一个特定子集,然后聚合工作在该子集上
找到所有售价高于10000美刀的车,同时也对这些车计算其平均价格
GET /cars/transactions/_search
{
"size": 0,
"query": {
"filtered": {
"filter": {
"range": {
"price": {
"gte": 10000
}
}
}
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
//返回结果
{
...
"hits": {
"total": 8,
"max_score": 0,
"hits": []
},
"aggregations": {
"avg_price": {
"value": 26500
}
}
}
- Filter桶(Filter Bucket)示例: 搜索结果必须要匹配ford,但是聚合结果必须要匹配ford以及售出时间为指定时间段
GET /cars/transactions/_search
{
"query": {
"match": {
"make": "ford"
}
},
"aggs": {
"recent_sales": {
"filter": {
"range": {
"sold": {
"from": "2014-03-01",
"to": "2014-05-20"
}
}
},
"aggs": {
"avg_prices": {
"avg": {
"field": "price"
}
}
}
}
}
}
//Result:
...
"hits": [
{
"_index": "cars",
"_type": "transactions",
"_id": "AVadmD-NR0VtE3lSJ2cx",
"_score": 1,
"_source": {
"price": 30000,
"color": "green",
"make": "ford",
"sold": "2014-05-18"
}
},
{
"_index": "cars",
"_type": "transactions",
"_id": "AVadmD-NR0VtE3lSJ2c2",
"_score": 1,
"_source": {
"price": 25000,
"color": "blue",
"make": "ford",
"sold": "2014-02-12"
}
}
]
},
"aggregations": {
"recent_sales": {
"doc_count": 1,
"avg_prices": {
"value": 30000
}
}
}
}
- 后置过滤器(Post Filter)
有一种过滤器只过滤搜索结果,而不过滤聚合呢?”这个问题的答案就是使用post_filter 过滤器会在查询执行完毕后生效(后置因此得名:在查询执行之后运行)。正因为它在查询执行后才会运行,所以它并不会影响查询作用域 - 因此就不会对聚合有所影响。
GET /cars/transactions/_search?search_type=count
{
"query": {
"match": {
"make": "ford"
}
},
//在query运行完成以后运行post_filter,并且不影响聚合的运行
"post_filter": {
"term" : {
"color" : "green"
}
},
//聚合是基于query运行,不受post_filter影响
"aggs" : {
"all_colors": {
"terms" : { "field" : "color" }
}
}
}
//运行结果
"hits": {
"total": 1,
"max_score": 0,
"hits": []
},
"aggregations": {
"all_colors": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "blue",
"doc_count": 1
},
{
"key": "green",
"doc_count": 1
}
]
}
}
}
post_filter元素是一个顶层元素,只会对搜索结果进行过滤。 查询部分呢用来找到所有ford汽车。然后我们根据一个terms聚合来得到颜色列表。因为聚合是在查询作用域中进行的,得到的颜色列表会反映出ford汽车的各种颜色。 最后,post_filter会对搜索结果进行过滤,只显示绿色的ford汽车。这一步发生在执行查询之后,因此聚合是不会被影响的。
最后:由于性能的原因post_filter尽量少用。
感谢:http://blog.csdn.net/dm_vincent/article/details/42757519
Missing 部分文档中不存在的字段的聚合
使用missing聚合统计过滤掉不存的字段
示例:仅供参考
% curl "$URI?pretty&search_type=count" -d '{
"aggregations": {
"event_dates": {
"date_histogram": {
"field": "date", "interval": "1M"
}
},
"missing_date": {
"missing": {
"field": "date"
}
}
}
}'
总结
在这一章我们主要涉及的是常用的聚合类型,以及常用的聚合的组合使用。
- 聚合的组合使用
- 两个大类的聚合: bucket(桶) and metrics(指标)
- metrics(指标)涉及到比较详细的统计计算,比如最大值,最小值等,以及近似计算,百分数计算,还有基数统计
- bucket(桶)是一种大的分类聚合,基于桶在进行详细的metrics(指标)聚合
- top_hits 作为子聚合使用,返回结果分组,比如返回兴趣广泛的Top 2
- significant_terms 基于统计的统计
- 单桶聚合 global, filter, filters, 和missing
Thanks: http://blog.csdn.net/dm_vincent/article/details/42387161 http://blog.csdn.net/dm_vincent/article/details/42757519 http://www.tianyiqingci.com/2016/04/11/esaggsapi/ http://www.cnblogs.com/richaaaard/p/5319299.html 参考资料集: http://www.cnblogs.com/richaaaard/category/783901.html http://blog.csdn.net/dm_vincent/article/category/2718099 http://www.cnblogs.com/xing901022/category/642865.html