Elasticsearch的数据组织解构
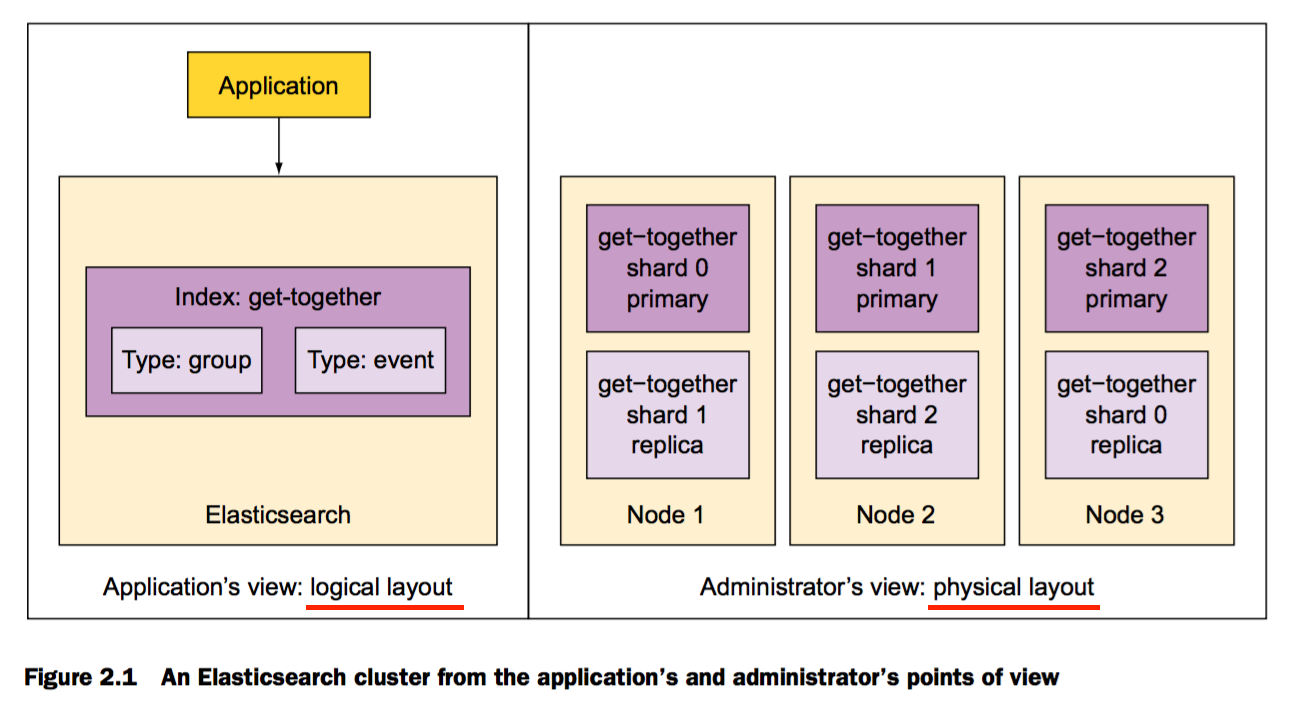
应用程序与Elasticsearch的交互图
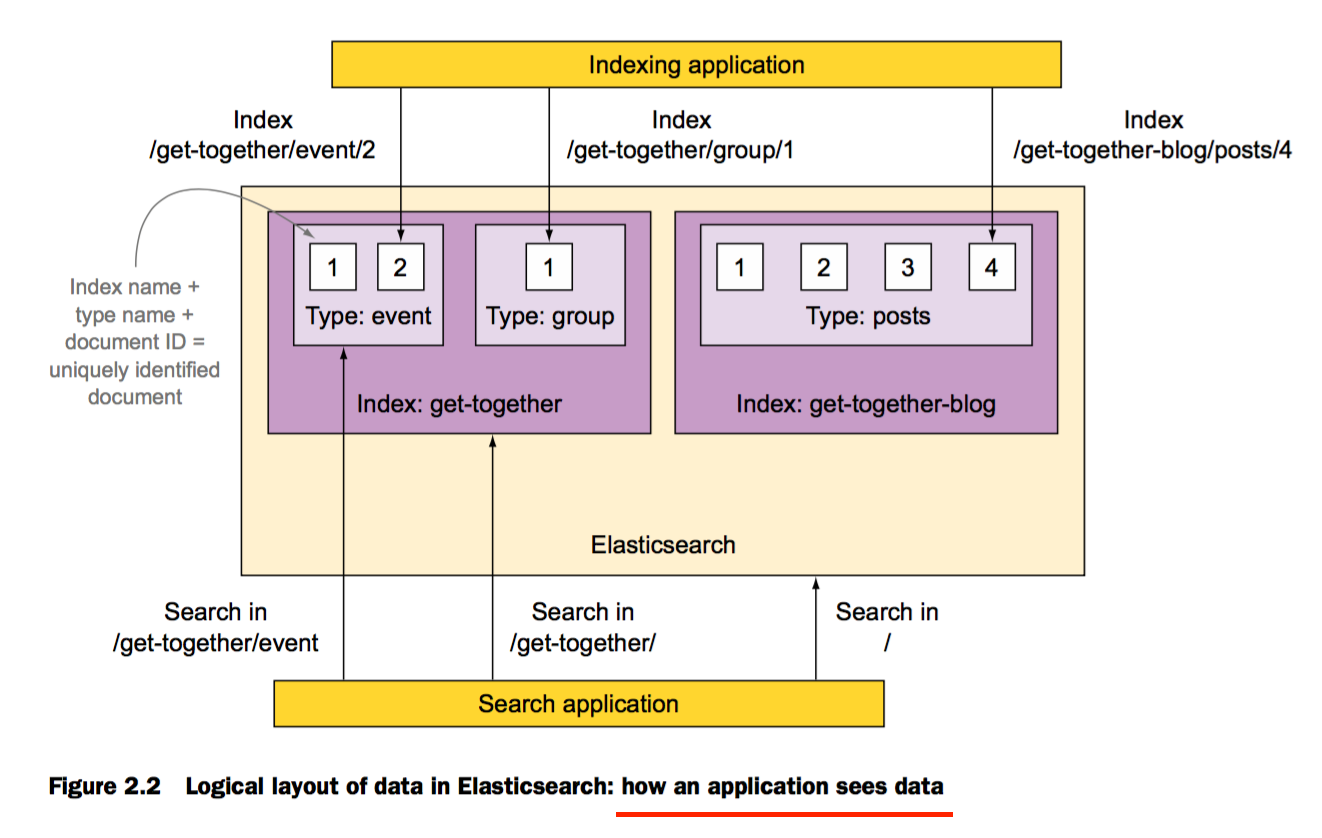
Elasticsearch是面向文档的
文档是search和index的最小单元
Document(文档相当于关系型数据库的每条记录)
Document(文档)在Elasticsearch中是schema-free的
Type(类型相当于关系型数据库的Table)
定义type下每个field的类型的过程称之为mapping,例如,name的类型被定义为string,在location下的geolocation字段类型被定义为 special geo_point
Index(索引相当于关系型数据库的database)
Indices是mapping好了的Type的容器,Elasticsearch的index是一个独立的文档集合块。很像关系型数据库。每个index存储在硬盘上其拥有相同的文件集合;在那儿存储所有mapping好的Type,和它自己的settings
Elasticsearch的物理结构:节点和分片
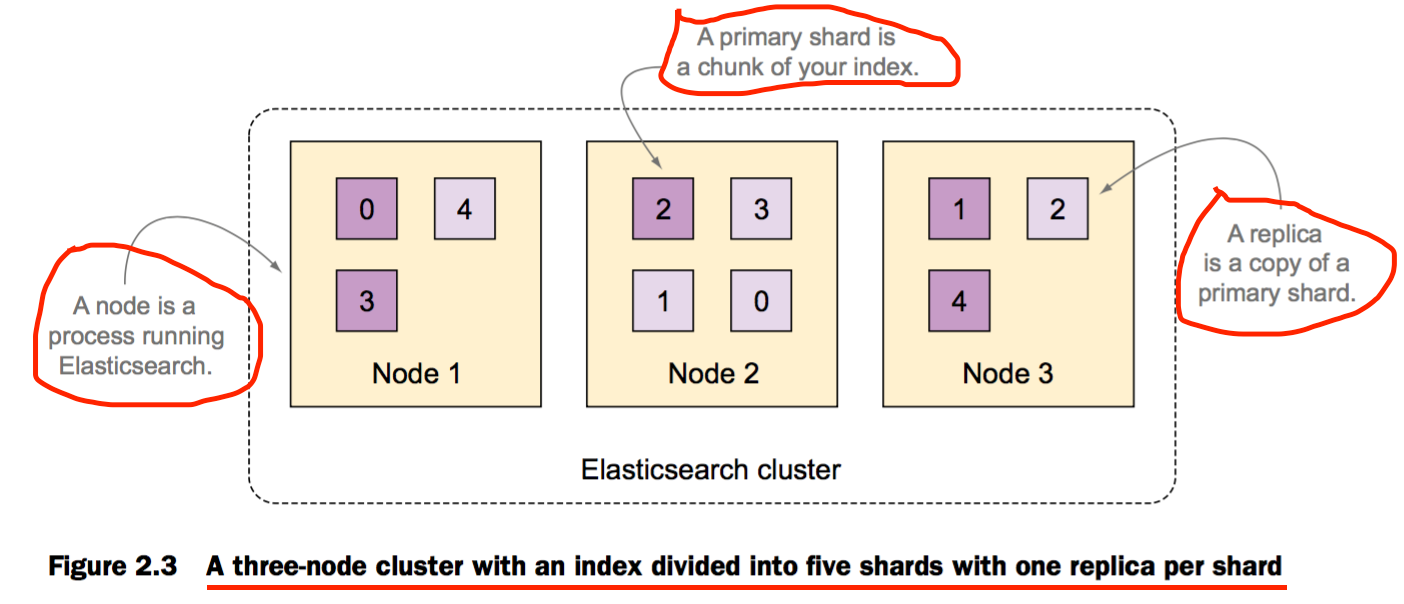
默认每个index被分布式存储在5个主分片中,并且每个主分片拥有一个复制集分片。也就是说默认一共有10个分片
复制集对于可靠性和搜索性能都是有益处的。从技术角度来说,分片是Lucene存储index数据的文件目录。分片也是Elasticsearch中节点间迁移的最小数据单元
文档实现索引的过程
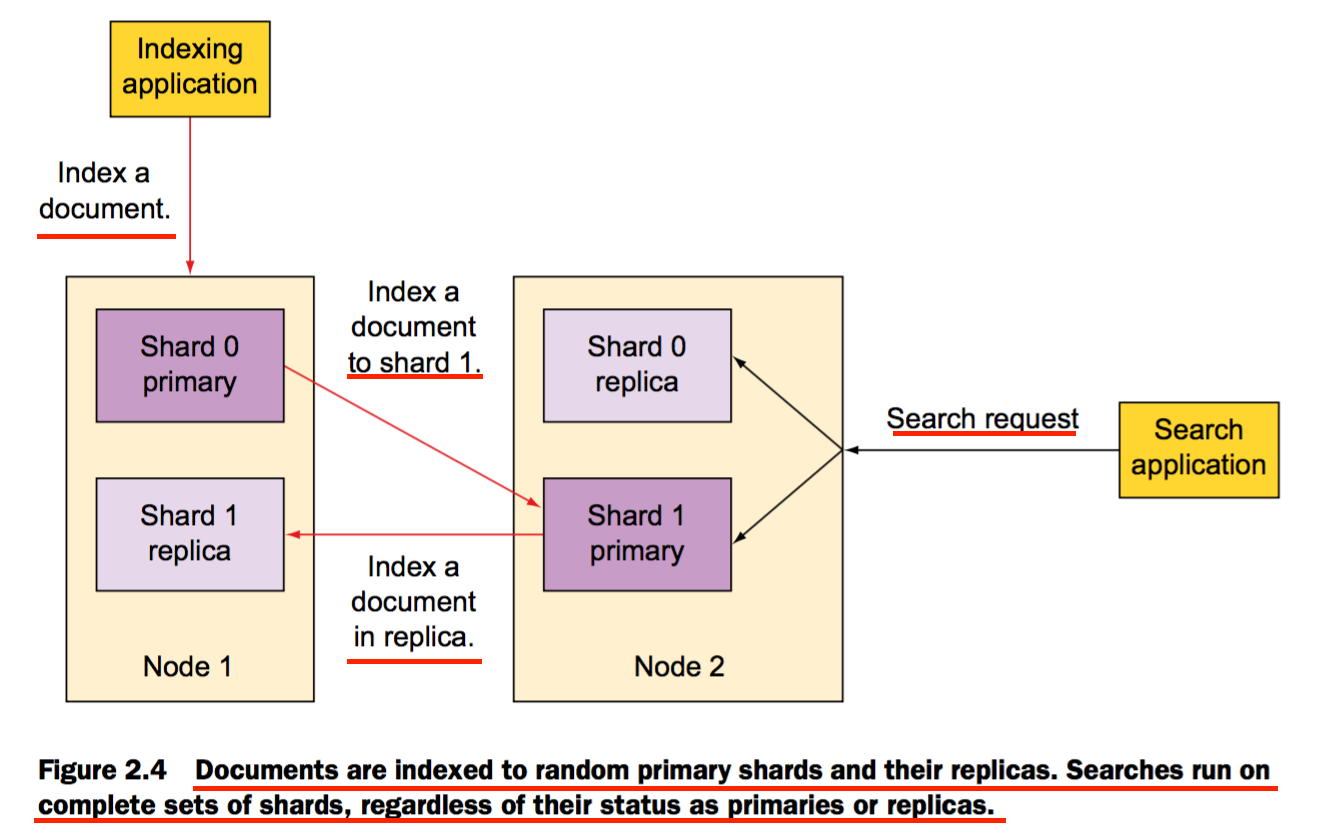
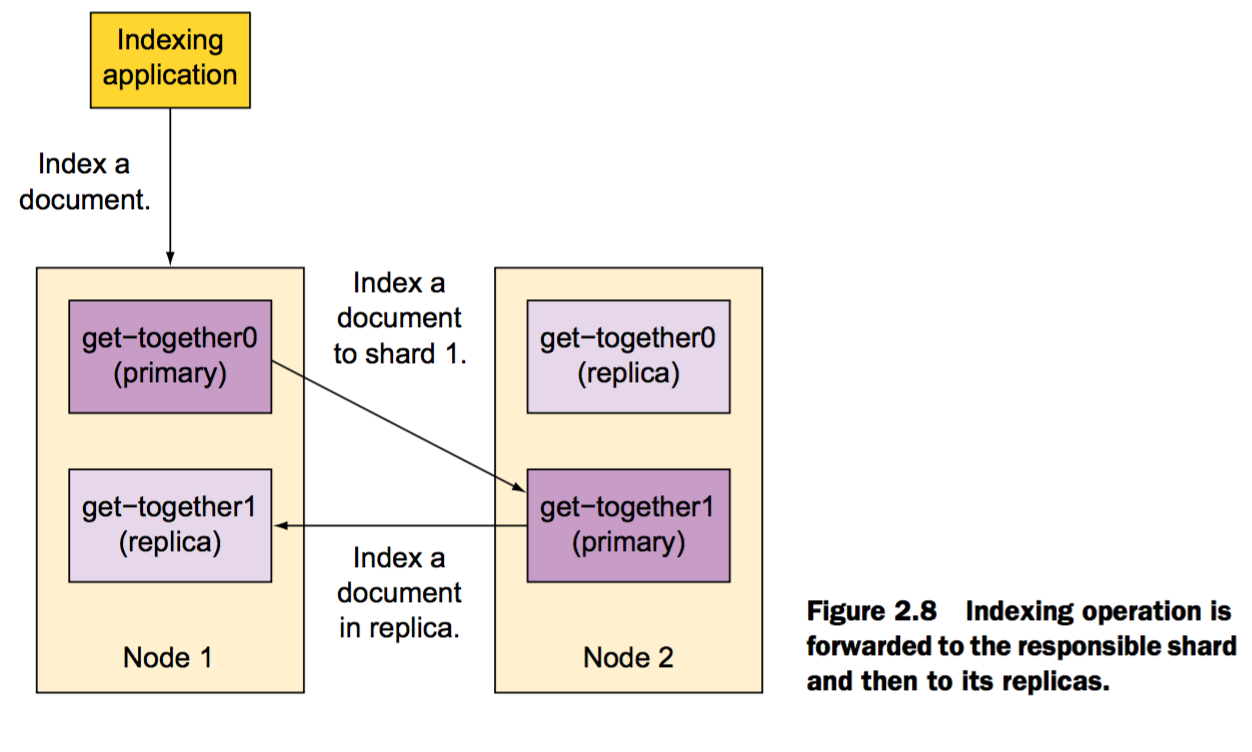
默认情况下,当你索引一个文档时,首先会发送到一个主分片上(该主分片的选择是基于文档ID的hash值)。并主分片也许被分配到不同的节点上,但是这一切对于应用程序来说都是透明的。
理解主分片和复制集分片
Elasticsearch 的最小处理单元就是分片
Elasticsearch的index被分割成多个分片。一个分片就是Lucene中的一个index,也就是说Elasticsearch的index是由多个Lucene的index构成。
分片要么是主分片要么是复制集分片。复制集分片是主分片的副本。复制集分片可以用于搜索,或者当该复制集分片对应的主分片挂掉时自动升级为主分片
复制集分片可以在运行时添加或移除,但是主分片不可以。
分片在集群中的分布
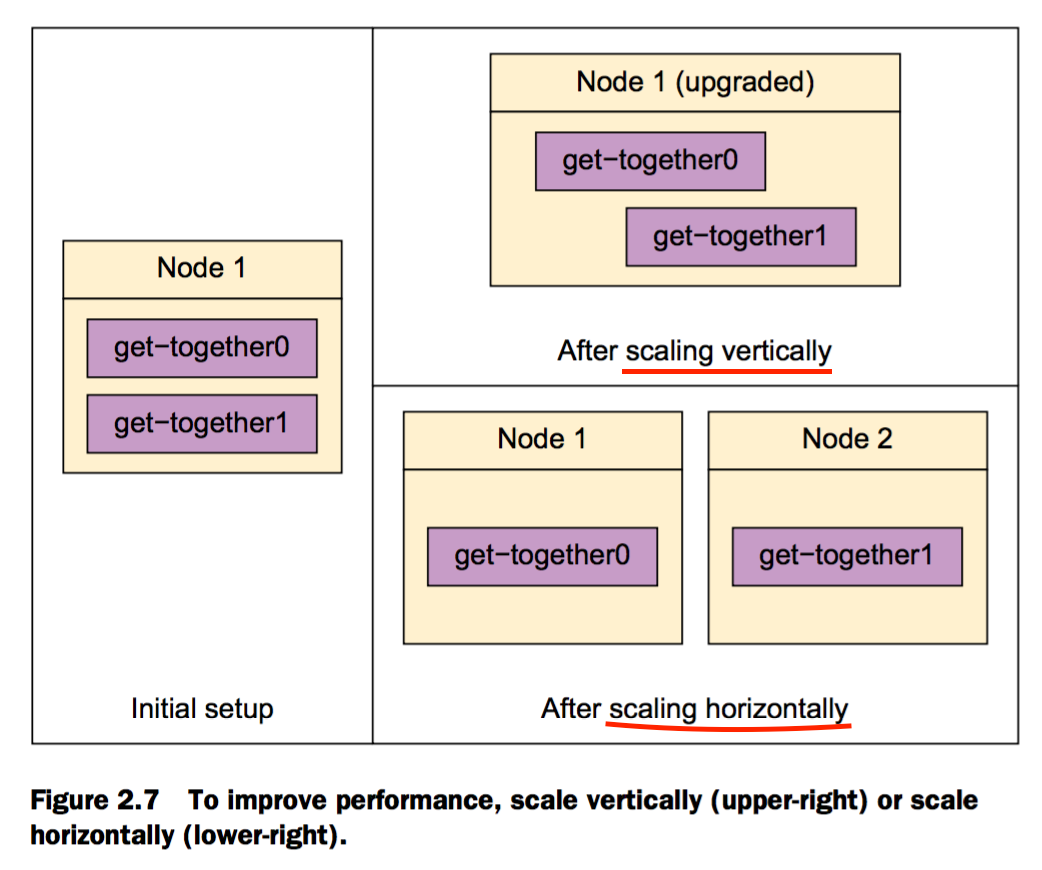
水平扩充
在现有集群中增加节点,称之为水平扩充
垂直扩充
升级节点的硬件配置,例如内存,硬盘,CPU等,称之为垂直扩充
分布式索引和搜索
分布式索引
分布式搜索
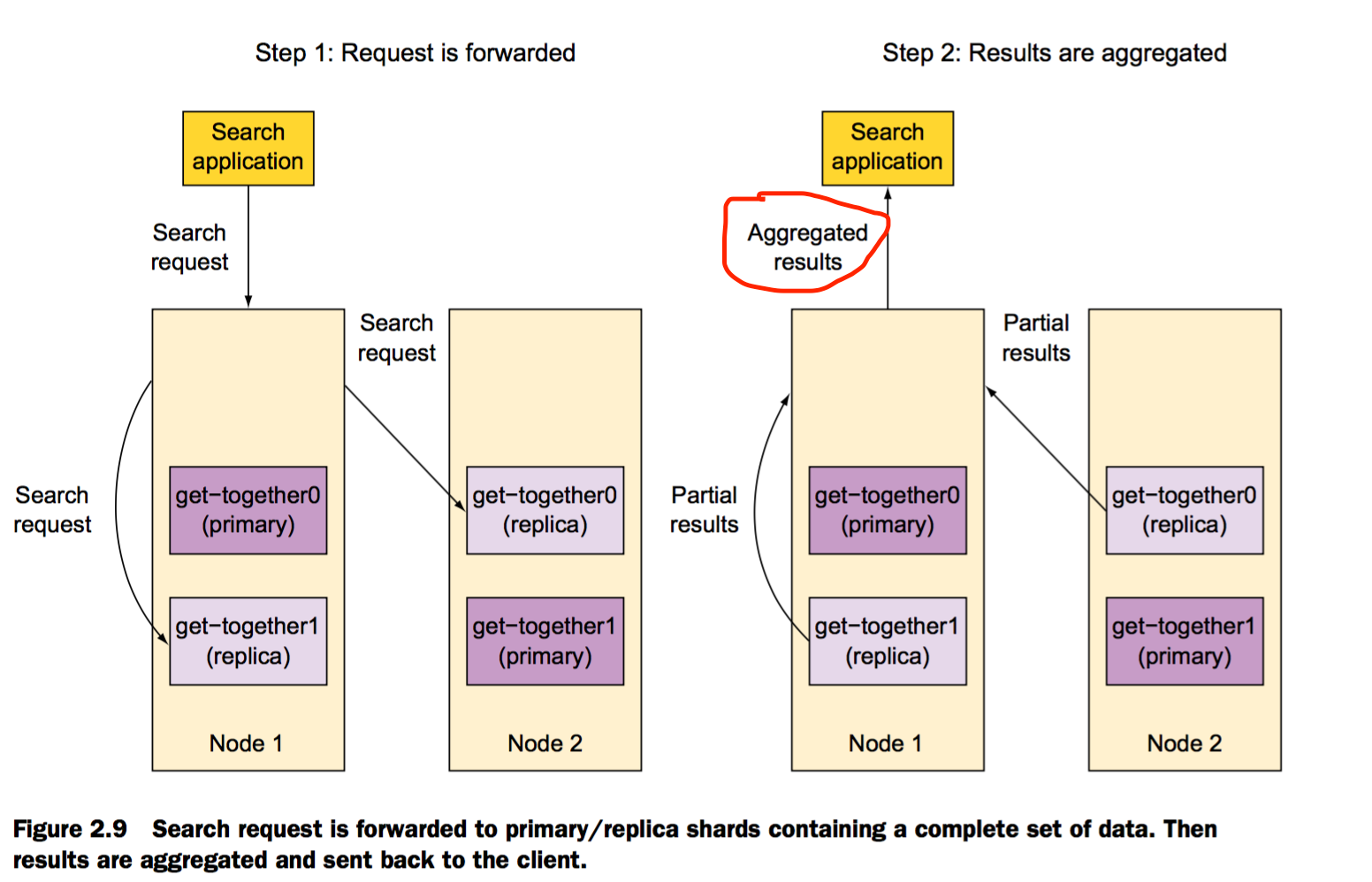
搜索时,接收到request的节点,转发request到包含所有数据的分片。根据round-robin算法,Elasticsearch 选择有效的分片并执行查询。上图所示,Elasticsearch汇集返回结果,并将其聚合成一个单独的响应返回给客户端应用程序。