什么是文本分析
概览自定义分析器使用标准组件分析文本的过程
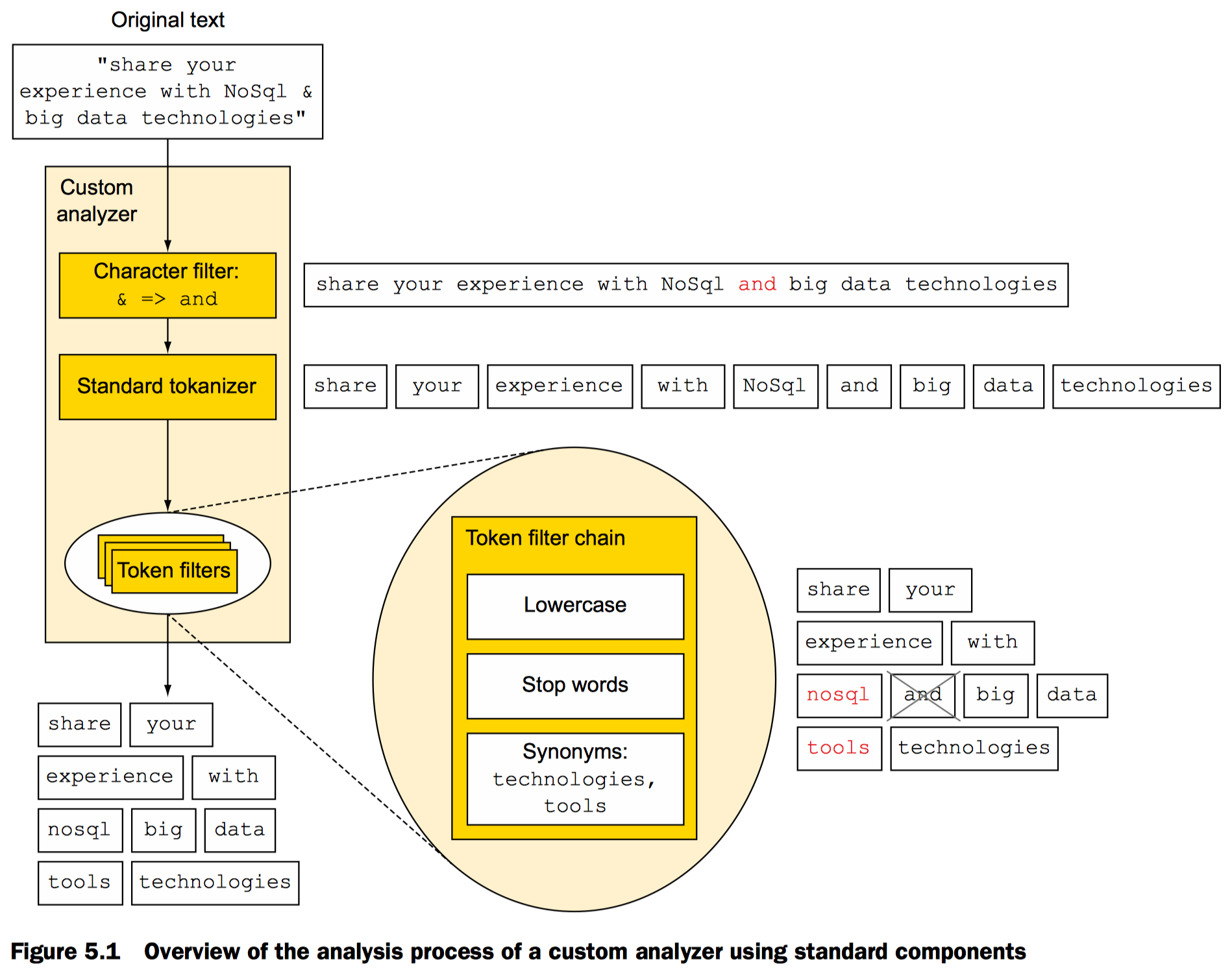
Character filtering 特殊字符过滤转换
比如将文本中的“&” 用“and”替换
分词
英文分词可以直接使用标准分词器,根据空白字符,特殊字符例如下划线等分词
Token过滤转换
对分词结果进行修正,添加和移除。例如把token转换成小写。分词结果可以应用多个不同的token filter。
Token 索引
分词完成后使用luence完成索引
一个或多个character filters, 一个tokenizer和若干token filters构成了分析器
查询像match和match_phrase会在搜索前做分词处理。而term和terms查询则不会。另外应用不同的分析器,在搜索时会呈现不同的结果。
对文档使用分析器
在mapping时可以为分析器配置独立的分词器和token filter,以及对特定字段配置分析器
两种分析器配置方式
- 针对特定的index配置分析器
- 在Elasticsearch配置文件中配置全局分析器
不管怎样配置自定义分析器,总之是必须配置的。要么在创建index时,要么稍后使用“put mapping API”创建
创建index时添加分析器
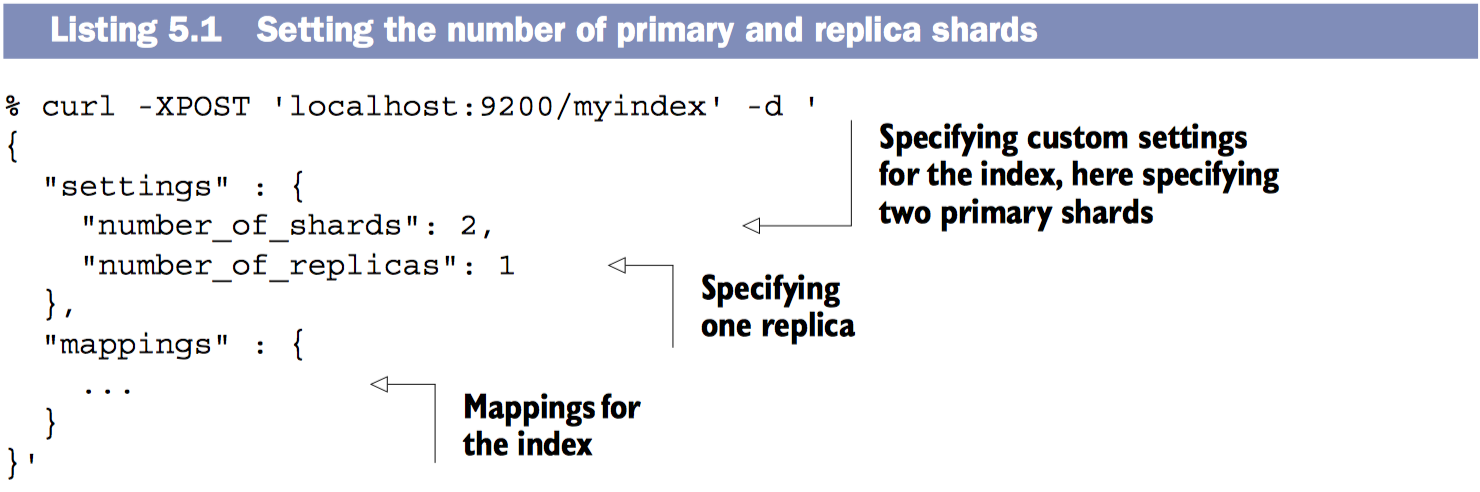
创建index时添加自定义分析器

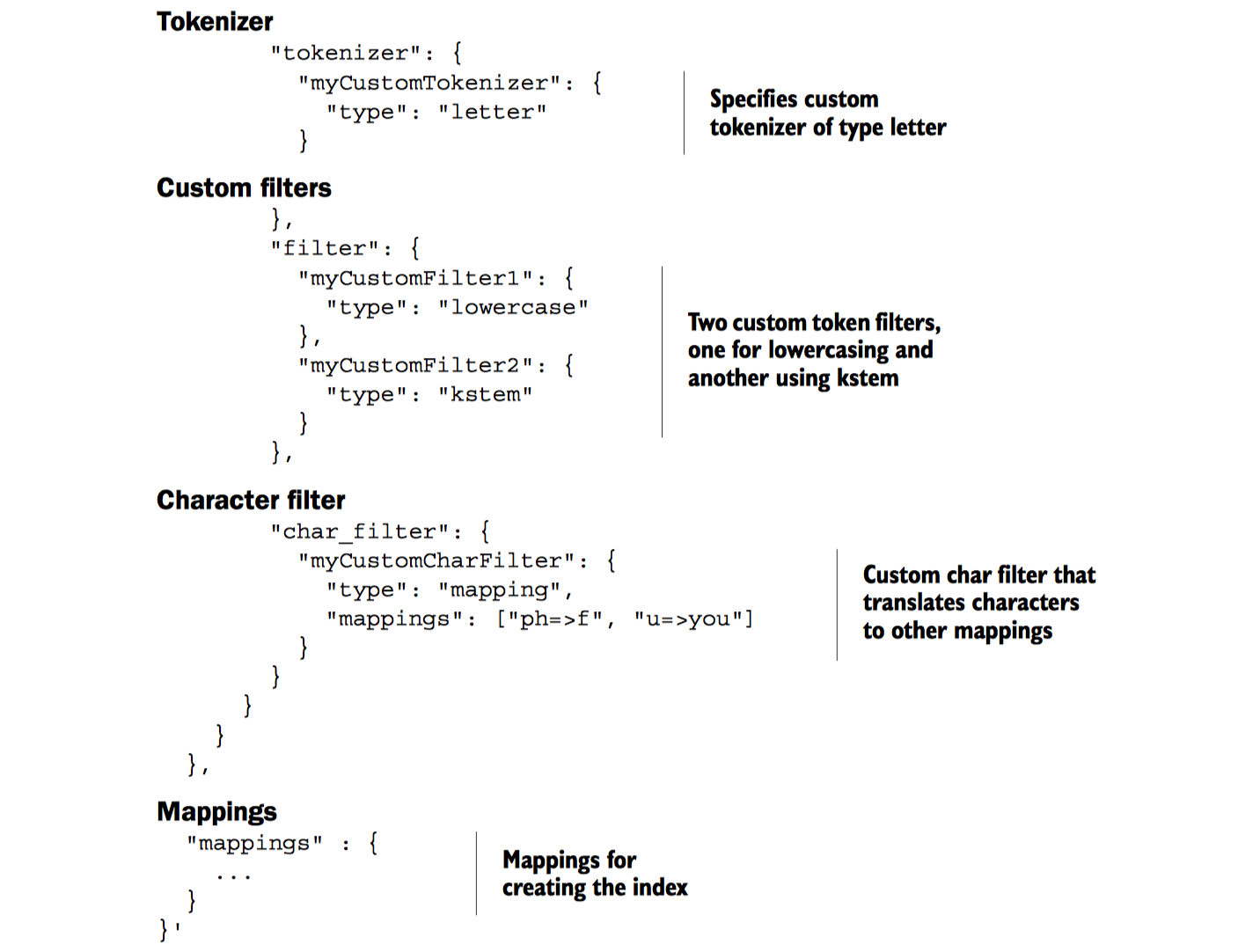 可以用不同的名称配置不同的分析器,然后组合成为自定义分析器。这将使得索引和搜索变的更加灵活(具体怎样配置有待进一步了解)
可以用不同的名称配置不同的分析器,然后组合成为自定义分析器。这将使得索引和搜索变的更加灵活(具体怎样配置有待进一步了解)
在Elasticsearch配置文件中配置分析器
权衡一下:在创建index时添加分析器,改变分析器无需重启Elasticsearch;在Elasticsearch配置文件中配置分析器,任何改动都需要重启Elasticsearch。总之根据需要配置即可
在Elasticsearch配置文件elasticsearch.yml中配置分析器
index:
analysis:
analyzer:
myCustomAnalyzer:
type: custom
tokenizer: myCustomTokenizer
filter: [
myCustomFilter1,
myCustomFilter2
]
char_filter: myCustomCharFilter
tokenizer:
myCustomTokenizer:
type: letter
filter:
myCustomFilter1:
type: lowercase
myCustomFilter2:
type: kstem
char_filter:
myCustomCharFilter:
type: mapping
mappings: ["ph=>f", "u =>you"]
在mapping中针对字段配置分析器
为description字段配置myCustomAnalyzer分析器
{
"mappings" : {
"document" : {
"properties" : {
"description" : {
"type" : "string",
"analyzer" : "myCustomAnalyzer"
}
}
}
}
}
配置name字段为不分析字段
index设定值not_analyzed,将使name的值作为一个独立的token而不被分词
{
"mappings" : {
"document" : {
"properties" : {
"name" : {
"type" : "string",
"index" : "not_analyzed"
}
}
}
}
}
-
使用多字段类型存放不同的分析文本 例如:你想用不分析的name字段排序,还想name字段还是分析可搜索的
$ curl -XPOST 'localhost:9200/get-together' -d ' { "mappings": { "group": { "properties": { "name": { "type": "string", "analyzer": "standard", //The original analysis, using the standard analyzer, can be left out and is the default. "fields": { "raw": { "index": "not_analyzed", //A raw version of the field, which isn’t analyzed "type": "string" } } } } } } }'
使用analyze API分析文本
使用analyze API向Elasticsearch发送文本,并指定分析器,分词器以及token filter,返回分词结果
举个例子:使用标准分析器分析文本“share your experience with NoSql & big data technologies.”
$ curl -XPOST 'localhost:9200/_analyze?analyzer=standard' -d 'share your experience with NoSql & big data technologies'
结果: share, your, experience, with, nosql, big, data, and technologies
{
"tokens": [{
"token": "share",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 1
}, {
"token": "your",
"start_offset": 6,
"end_offset": 10,
"type": "<ALPHANUM>",
"position": 2
}, {
"token": "experience",
"start_offset": 11,
"end_offset": 21,
"type": "<ALPHANUM>",
"position": 3
}, {
"token": "with",
"start_offset": 22,
"end_offset": 26,
"type": "<ALPHANUM>",
"position": 4
}, {
"token": "nosql",
"start_offset": 27,
"end_offset": 32,
"type": "<ALPHANUM>",
"position": 5
}, {
"token": "big",
"start_offset": 35,
"end_offset": 38,
"type": "<ALPHANUM>",
"position": 6
}, {
"token": "data",
"start_offset": 39,
"end_offset": 43,
"type": "<ALPHANUM>",
"position": 7
}, {
"token": "technologies",
"start_offset": 44,
"end_offset": 56,
"type": "<ALPHANUM>",
"position": 8
}]
}
选择分析器
使用自定义分析器创建index,将可以一直通过名称使用这个分析器,举个🌰:使用名字为myCustomAnalyzer的自定义分析器
$ curl -XPOST 'localhost:9200/get-together/_analyze?analyzer=myCustomAnalyzer' –d 'share your experience with NoSql & big data technologies'
部分组合创建临时分析器
使用analysis API指定tokenizer和若干个token filters分析文本
$ curl -XPOST 'localhost:9200/ _analyze?tokenizer=whitespace&filters=lowercase,reverse' -d 'share your experience with NoSql & big data technologies'
返回结果: erahs, ruoy, ecneirepxe, htiw, lqson, &, gib, atad, seigolonhcet
基于字段的mapping分析文本
字段description的mapping
...other mappings...
"description": {
"type": "string",
"analyzer": "myCustomAnalyzer"
}
可以指定一个和字段相关的分析器来分析文本
$ curl -XPOST 'localhost:9200/get-together/_analyze?field=description' –d ' share your experience with NoSql & big data technologies'
自定义分析器能自行被应用是因为它和description字段相关
使用分词器和token filter可以创建自定义分析器
使用_termvector接口了解更多term信息
包括term在文档中在index中出现频的率,出现的位置
例子:id为1的文档的term信息
$ curl 'localhost:9200/get-together/group/1/_termvector?pretty=true'
{
"_index": "get-together",
"_type": "group",
"_id": "1",
"_version": 1,
"found": true,
"term_vectors": {
"description": { //description字段的terms信息
"field_statistics": { //该字段的terms的统计信息
"sum_doc_freq": 197, //每个term在该字段出现的文档的总和
"doc_count": 12, //包含该字段的文档数量
"sum_ttf": 209 //所有term在该字段出现频率的总和
},
"terms": { //字段description包含的所有term
"about": { //term内容
"term_freq": 1, //在该字段中term出现的次数
"tokens": [{ //term在字段中出现的位置
"position": 16,
"start_offset": 90,
"end_offset": 95
}]
},
"and": {
"term_freq": 1,
"tokens": [{
"position": 13,
"start_offset": 75,
"end_offset": 78
}]
},
"clojure": {
"term_freq": 2,
"tokens": [{
"position": 2,
"start_offset": 9,
"end_offset": 16
}, {
"position": 17,
"start_offset": 96,
"end_offset": 103
}]
},
...More terms omitted
}
}
}
}
获取指定字段的term统计信息
% curl 'localhost:9200/get-together/group/1/_termvector?pretty=true' -d '
{
"fields" : ["description","tags"],
"term_statistics" : true
}'
具有代表性的部分返回结果展示
"about" : { // 字段值中出现的term
"doc_freq" : 2, // term出现的文档总数
"ttf" : 2, // 在index中出现的总数
"term_freq" : 1,
"tokens" : [
{
"position" : 16,
"start_offset" : 90,
"end_offset" : 95
}
]
}
分析器,分词器和token过滤器
内置分析器
分析器概览
分析器由可选的字符过滤器,分词器和若干个token过滤器组成
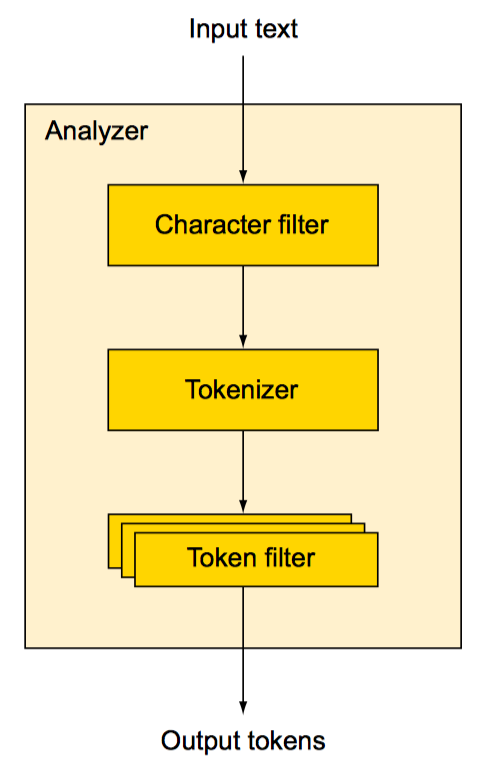
| Analyzer | 描述 |
|---|---|
| STANDARD | 默认分析器 |
| SIMPLE | 使用非字母字符分词并自动转换为小写,不适合东亚语系,只适用于欧美语系 |
| WHITESPACE | whitespace分析器使用空白字符分词 |
| STOP | stop 分析器和simple分析器相似,额外还可以使用stopwords进行分词 |
| KEYWORD | keyword分析器将整个字段生成一个token. 与其使用keyword分词器还不如直接将字段设置为not_analyzed |
| PATTERN | pattern分析器,可以自定义pattern,用于分词 |
| LANGUAGE AND MULTILINGUAL | Elasticsearch支持包括中英等多种语言,指定语言名称即可使用该语言分析器,例如english,chinese |
| SNOWBALL | snowball 分析器使用 standard tokenizer 和 token filter (就像 standard分析器), 外加 lowercase token filter和 stop filter; 也使用snowball stemmer stems文本 |
分词
- STANDARD TOKENIZER standard分词器是基于英语语法的分词器,适用于欧美语言。也能处理Unicode文本,默认最大长度255,也能移除标点符号。
- KEYWORD Keyword是一个简单的分词器,它把整个文本作为一个单独的token
- LETTER letter分词器,剔除非字母字符进行分词。例如“Hi, there.”的分词结果为: Hi和there
- LOWERCASE lowercase分词器由letter分词器和lowercase token filter组成,目的是提高分词的性能
- WHITESPACE whitespace分词器使用空白字符分词像space, tab, 换行符等.该分词器不移除任何标点符号 (有待进一步验证)
-
PATTERN pattern分词器任意设置pattern用于分词.pattern应当包含匹配空格字符的部分; 例子: 自定义pattern分词器
$ curl -XPOST 'localhost:9200/pattern' -d ' { "settings": { "index": { "analysis": { "tokenizer": { "pattern1": { "type": "pattern", "pattern": "\\.-\\." } } } } } }' $ curl -XPOST 'localhost:9200/pattern/_analyze?tokenizer=pattern1' -d 'breaking.-.some.-.text'分词结果: breaking, some, text
-
UAX URL EMAIL UAX URL email分词器能确保email和URL被作为单独的token,而不是被分词
对email,url字符串使用
standard tokenizer/* * EMAIL */ $ curl -XPOST 'localhost:9200/_analyze?tokenizer=standard' -d 'john.smith@example.com' //分词结果: john.smith and example.com /* * URL */ $ curl -XPOST 'localhost:9200/_analyze?tokenizer=standard' -d 'http://example.com?q=foo' //分词结果: http, example.com, q, and foo对email,url字符串使用
UAX URL email tokenizer$ curl -XPOST 'localhost:9200/_analyze?tokenizer=uax_url_email' -d 'john.smith@example.com http://example.com?q=bar' //分词结果: 留意type属性 { "tokens": [{ "token": "john.smith@example.com", "start_offset": 1, "end_offset": 23, "type": "<EMAIL>", "position": 1 }, { "token": "http://example.com?q=bar", "start_offset": 24, "end_offset": 48, "type": "<URL>", "position": 2 }] } -
PATH HIERARCHY path hierarchy分词器可以对文件系统路径进行分词
$ curl 'localhost:9200/_analyze?tokenizer=path_hierarchy' \ -d '/usr/local/var/log/elasticsearch.log' //分词结果: /usr, /usr/local, /usr/local/var, /usr/local/var/log, and /usr/ local/var/log/elasticsearch.log.也就是说用户搜索 “/usr/local/var/log/es.log”时和“/usr/local/var/log/elasticsearch.log”共享token
Token filters
Token filters 接收来自分词器的结果并为索引准备数据
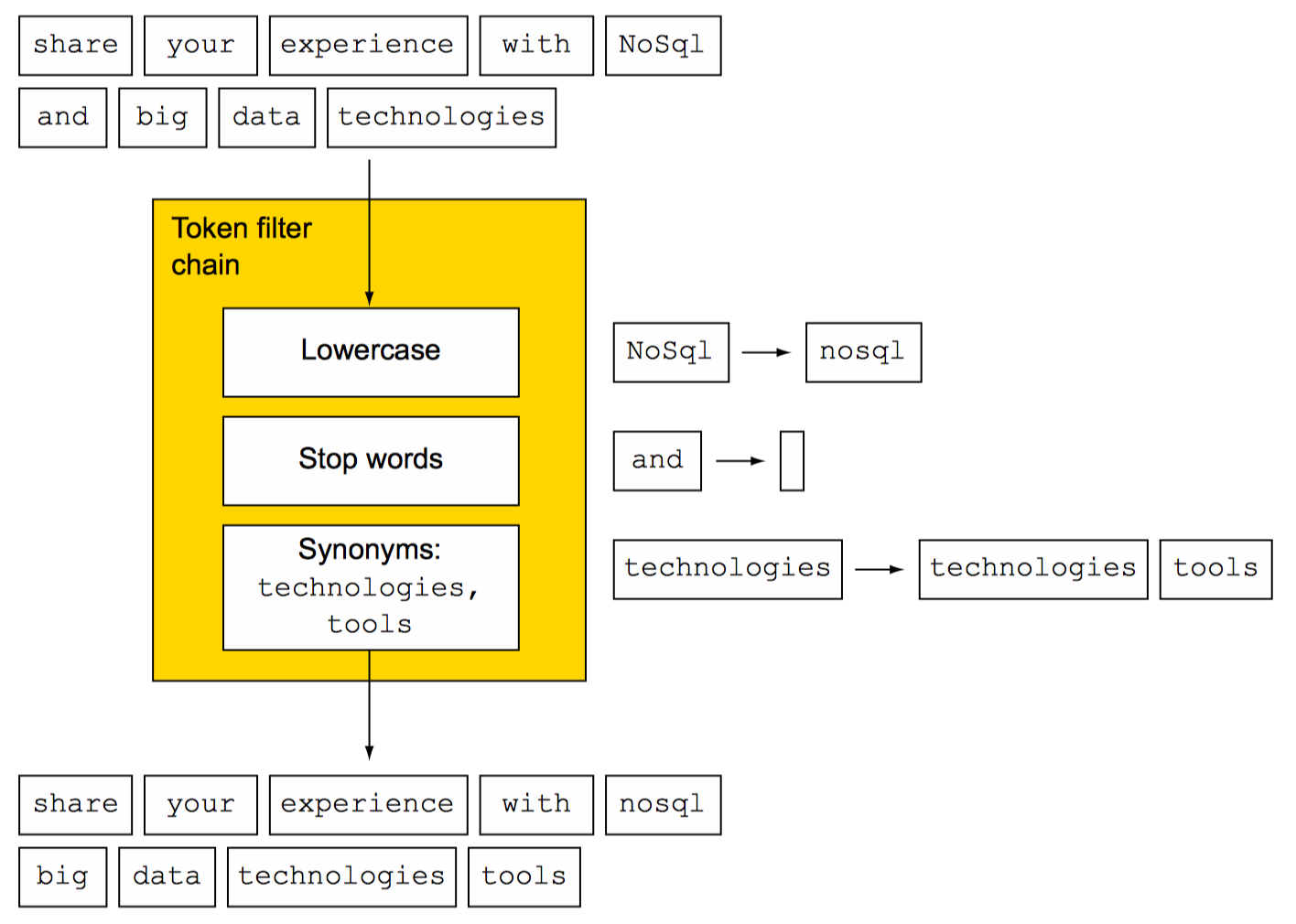
-
STANDARD 实际上啥都不干
- LOWERCASE lowercase token filter将token转换为小写
-
LENGTH The length token filter 移除超出规定长度的token
例如,设定token的最小长度为2最大长度8, 任何小于2个字符或大于8个字符的token都会被移除
$ curl -XPUT 'localhost:9200/length' -d '{ "settings": { "index": { "analysis": { "filter": { "my-length-filter": { "type": "length", "max": 8, "min": 2 } } } } } }'自定义token filter叫做my-length-filter 设定token的长度范围为2到8
$ curl 'localhost:9200/length/_analyze?tokenizer=standard&filters=my-length- filter&pretty=true' -d 'a small word and a longerword' //分词结果: small, word, and -
STOP stop token filter从token结果中移除stopwords 英语中默认的stopwords列表:
a, an, and, are, as, at, be, but, by, for, if, in, into, is, it, no, not, of, on, or, such, that, the, their, then, there, these, they, this, to, was, will, with也可以使用自定义的stopwords列表构建自定义的token filter
$ curl - XPOST 'localhost:9200/stopwords' - d '{ "settings": { "index": { "analysis": { "analyzer": { "stop1": { "type": "custom", "tokenizer": "standard", "filter": ["my-stop-filter"] } }, "filter": { "my-stop-filter": { "type": "stop", "stopwords": ["the", "a", "an"] } } } } } }'自定义的stopwords列表可以存放在文件中,使用绝对路径或相对路径引用该文件。文件中每个stopword占一行,而且文件必须是UTF-8编码。示例如下:
$ curl -XPOST 'localhost:9200/stopwords' -d '{ "settings": { "index": { "analysis": { "analyzer": { "stop1": { "type": "custom", "tokenizer": "standard", "filter": ["my-stop-filter"] } }, "filter": { "my-stop-filter": { "type": "stop", "stopwords_path": "config/stopwords.txt" } } } } } }' - TRUNCATE, TRIM, AND LIMIT TOKEN COUNT
truncatetoken filter可以使用设定的长度裁剪token,默认设定的长度是10个字符trimtoken filter移除token前后的空白字符limit token counttoken filter 限制最多能被索引的token的数量。如果设置 max_token_count参数的值为8,将只有前八个token会被索引,默认max_token_count参数的值为1
-
REVERSE reverse token filter可以翻转token. 这个有特定用途,对于这样的“bar”通配符搜索Lucene性能不佳,但是可以“rab”这样搜索一个被翻转的字段搜索性能将会提高,示例如下:
$ curl 'localhost:9200/_analyze?tokenizer=standard&filters=reverse' -d 'Reverse token filter' { "tokens": [{ "token": "esreveR", //“Reverse”被翻转 "start_offset": 0, "end_offset": 7, "type": "<ALPHANUM>", "position": 1 }, { "token": "nekot", //“token”被翻转 "start_offset": 8, "end_offset": 13, "type": "<ALPHANUM>", "position": 2 }, { "token": "retlif", //“filter”被翻转 "start_offset": 14, "end_offset": 20, "type": "<ALPHANUM>", "position": 3 }] }如你所见token都被翻转,但顺序还是保持不变
-
UNIQUE unique token filter 去除重复token;只保留初次匹配的token,移除所有未来出现的
$ curl 'localhost:9200/_analyze?tokenizer=standard&filters=unique' -d 'foo bar foo bar baz' //Result: { "tokens": [{ "token": "foo", "start_offset": 0, "end_offset": 3, "type": "<ALPHANUM>", "position": 1 }, { "token": "bar", "start_offset": 4, "end_offset": 7, "type": "<ALPHANUM>", "position": 2 }, { "token": "baz", "start_offset": 16, "end_offset": 19, "type": "<ALPHANUM>", "position": 3 }] } -
ASCII FOLDING ascii folding token filter 转换Unicode字符为等价的ASCII字符
$ curl 'localhost:9200/_analyze?tokenizer=standard&filters=asciifolding' -d 'ünicode' { "tokens" : [{ "token" : "unicode", "start_offset" : 0, "end_offset" : 7, "type" : "<ALPHANUM>", "position" : 1 }] } -
SYNONYM synonym(同义词) token filter 替换同义词,但token位置还是使用原词的位置 无synonym token filter的示例:
$ curl 'localhost:9200/_analyze?analyzer=standard' -d'I own that automobile' //Result: { "tokens": [{ "token": "i", "start_offset": 0, "end_offset": 1, "type": "<ALPHANUM>", "position": 1 }, { "token": "own", "start_offset": 2, "end_offset": 5, "type": "<ALPHANUM>", "position": 2 }, { "token": "that", "start_offset": 6, "end_offset": 10, "type": "<ALPHANUM>", "position": 3 }, { "token": "automobile", "start_offset": 11, "end_offset": 21, "type": "<ALPHANUM>", "position": 4 }] }自定义分析器,并定义synonym(同义词) token filter
$ curl - XPOST 'localhost:9200/syn-test' - d '{ "settings": { "index": { "analysis": { "analyzer": { "synonyms": { "type": "custom", "tokenizer": "standard", "filter": ["my-synonym-filter"] } }, "filter": { "my-synonym-filter": { "type": "synonym", "expand": true, "synonyms": ["automobile=>car"] //同义词定义 } } } } } }'使用synonym(同义词) token filter的示例:
$ curl 'localhost:9200/syn-test/_analyze?analyzer=synonyms' -d 'I own that automobile' //Result: { "tokens": [{ "token": "i", "start_offset": 0, "end_offset": 1, "type": "<ALPHANUM>", "position": 1 }, { "token": "own", "start_offset": 2, "end_offset": 5, "type": "<ALPHANUM>", "position": 2 }, { "token": "that", "start_offset": 6, "end_offset": 10, "type": "<ALPHANUM>", "position": 3 }, { "token": "car", "start_offset": 11, //注意start_offset和end_offset是用automobile算出来的 "end_offset": 21, "type": "SYNONYM", "position": 4 }] }上例中是同义词替换,也有可能是在token 列表中添加同义词。例如不是automobile=>car 而是automobile,car
Ngrams, edge ngrams, and shingles
在Elasticsearch中Ngrams和edge ngrams是两种更唯一的分词方式,Ngrams将token分解成多个子token ngram和edge ngram filter可以指定min_gram和max_gram.该配置控制token被分割的大小.
示例:
1-grams应用于“spaghetti”结果是s, p, a, g, h, e, t, t, i.
bigrams (两个字符分割)应用于 “spaghetti”结果是sp, pa, ag, gh, he, et, tt, ti
以三个字符分割 (被称作trigrams)应用于 “spaghetti”结果是spa, pag, agh, ghe, het, ett, tti
指定 min_gram是2, max_gram是3应用于“spaghetti” 结果是: sp, spa, pa, pag, ag, agh, gh, ghe, he, het, et, ett, tt, tti, ti
Edge ngrams
A variant to the regular ngram splitting called edge ngrams builds up ngrams only from the front edge. Edge ngrams是ngram的一种变体,它是从前面的字符开始分割的。例如字符“spaghetti” min_gram和max_gram 分别设置为2和6,得到的结果是: sp, spa, spag, spagh, spaghe 设置side属性可以使其从后向前分割。
Ngram settings
示例: 配置edge ngram 设置 min_gram和max_gram 参数
$ curl -XPOST 'localhost:9200/ng' -d' {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index": {
"analysis": {
"analyzer": {
"ng1": {
"type": "custom",
"tokenizer": "standard",
"filter": ["reverse", "ngf1", "reverse"] //配置token filter
}
},
"filter": {
"ngf1": {
"type": "edgeNgram",
"min_gram": 2, //设置edge ngram token filter的最大最小字符长度
"max_gram": 6
}
}
}
}
}
}'
Shingles
shingles token filter和ngrams是类似的但是token级别的。例如文本“foo bar baz”,设置min_shingle_size为2,max_shingle_size为3 token结果如下:foo, foo bar, foo bar baz, bar, bar baz, baz 默认shingles filter包含了原始的token,可以通过设置参数output_unigrams为false使原始的token不显示. min_shingle_size必须大于等于2
示例:
$ curl -XPOST 'localhost:9200/shingle' -d '{
"settings": {
"index": {
"analysis": {
"analyzer": {
"shingle1": {
"type": "custom",
"tokenizer": "standard",
"filter": ["shingle-filter"]
}
},
"filter": {
"shingle-filter": {
"type": "shingle",
"min_shingle_size": 2,
"max_shingle_size": 3,
"output_unigrams": false
}
}
}
}
}
}'
$ curl -XPOST 'localhost:9200/shingle/_analyze?analyzer=shingle1' -d 'foo bar baz'
//返回结果
{
"tokens": [{
"token": "foo bar",
"start_offset": 0,
"end_offset": 7,
"type": "shingle",
"position": 1
}, {
"token": "foo bar baz",
"start_offset": 0,
"end_offset": 11,
"type": "shingle",
"position": 1
}, {
"token": "bar baz",
"start_offset": 4,
"end_offset": 11,
"type": "shingle",
"position": 2
}]
}
Stemming
Stemming返回一个单词的词根.示例,单词 “administrations,” 词根是“administr.” 这样就能匹配到所有词根为administr的单词, 比如 “administrator,” “administration,”和 “administrate.” Stemming将使得搜索更灵活.
Algorithmic stemming
Elasticsearch 当前支持三种不同算法的stemmers分别是: snowball filter, porter stem filter, 和kstem filter.
对比三种算法的stemmers
| stemmer | administrations | administrators | Administrate |
|---|---|---|---|
| snowball | administr | administr | Administer |
| porter_stem | administr | administr | Administer |
| kstem | administration | administrator | Administrate |
示例:
curl -XPOST 'localhost:9200/_analyze?tokenizer=standard&filters=kstem' -d 'administrators'
使用词典实现Stemming
在Elasticsearch中可以使用hunspell token filter结合词典实现stemming.那么steming的质量将直接与词典相关,并且只能stem词典中的词汇
使用hunspell分析器创建索引:
$ curl -XPOST 'localhost:9200/hspell' -d '{
"analysis": {
"analyzer": {
"hunAnalyzer": {
"tokenizer": "standard",
"filter": ["lowercase", "hunFilter"]
}
},
"filter": {
"hunFilter": {
"type": "hunspell",
"locale": "en_US",
"dedup": true
}
}
}
}'
hunspell词典放置于路径
测试配置是否正常
curl -XPOST 'localhost:9200/hspell/_analyze?analyzer=hunAnalyzer' - d 'administrations'
重写stem结果
-
通过指定keyword marker token filter使strem结果失效
-
手工指定规则stem单词
总结
- 分析是文本转化为token的过程
- 每个字段通过mapping设置分析器
- 分析器由一系列处理链条构成,包括分词器,字符过滤器和token filter
- 字符过滤器被用于分词之前处理字符串
- 分词器用于分词
- Token filters处理分词器产生的结果
- Ngram token filters返回单词的词根token
- Edge ngrams和ngrams相似,但只从单词的开始和结尾分词
- Shingles和ngrams也类似但是短语级别