详解搜索请求
确定搜索范围
所有的搜索请求使用REST API的_search接口。请求方法使用GET或者POST
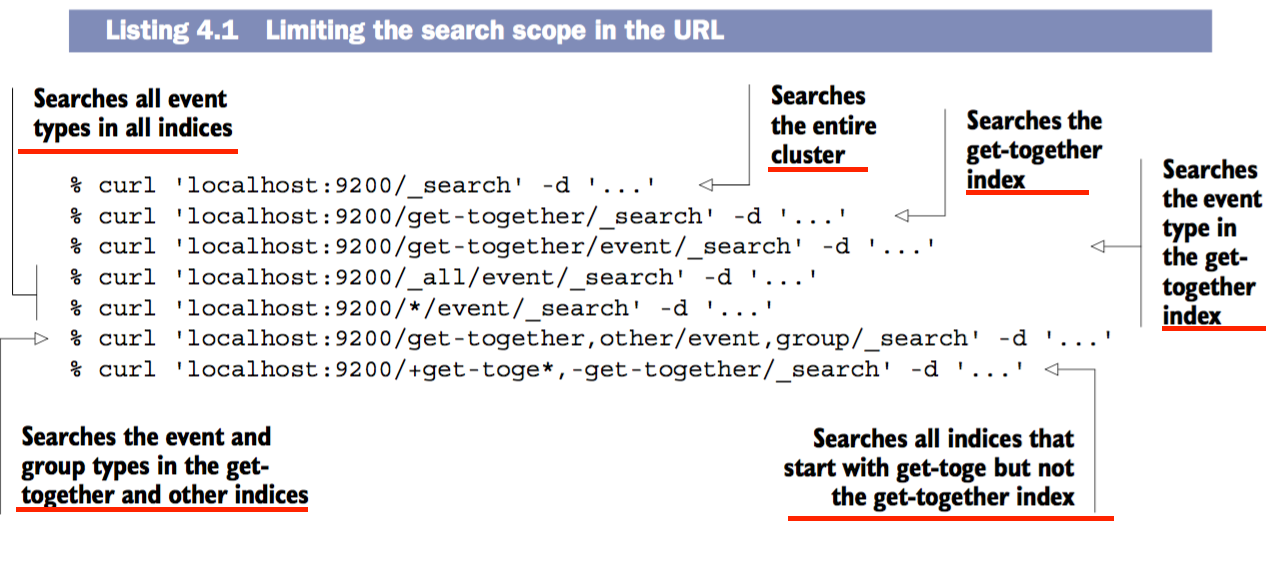 就性能而言,查询时index和type的数量越少,响应越快。原因是每一个请求都会被发送到index所在的分片上,那么请求越多的index,意味着需要越多的分片。
就性能而言,查询时index和type的数量越少,响应越快。原因是每一个请求都会被发送到index所在的分片上,那么请求越多的index,意味着需要越多的分片。
搜索请求的基本参数
- query — 搜索请求的最重要的参数, 对于该参数进行配置可以使搜索返回基于score的最优结果;配置该参数也可以过滤掉不需返回的结果
- size — 用于配置返回结果的数量.
- from — 和参数size一起使用,用于分页搜索结果。但是请注意,为了返回第二页的十个结果,Elasticsearch必须计算前20个结果。假如搜索结果集很大,那么获取中间页的内容代价将会非常高。(
这个分页性能问题值得推敲,不应该是这样的) - _source — 配置返回结果里包含那些字段,默认返回全部字段。
- sort — 默认排序是基于文档的score分数。
搜索结果的起始位置和单页搜索结果的数量
例如,假如设置from的值是7,size的值是5.Elasticsearch将返回第八,第九,第十,第十一,第十二个结果(from参数起始值是0)。如果没有设置from和size,Elasticsearch默认设置from为0,size为10
基于URL的搜索请求 基于URL的搜索请求的好处就是能够快捷使用,但是许多搜索的特性不能使用 示例:
-
获取第二页的10个结果

-
获取10个按date升序排列的结果

-
获取10个仅包含字段title和date并按date升序排列的结果
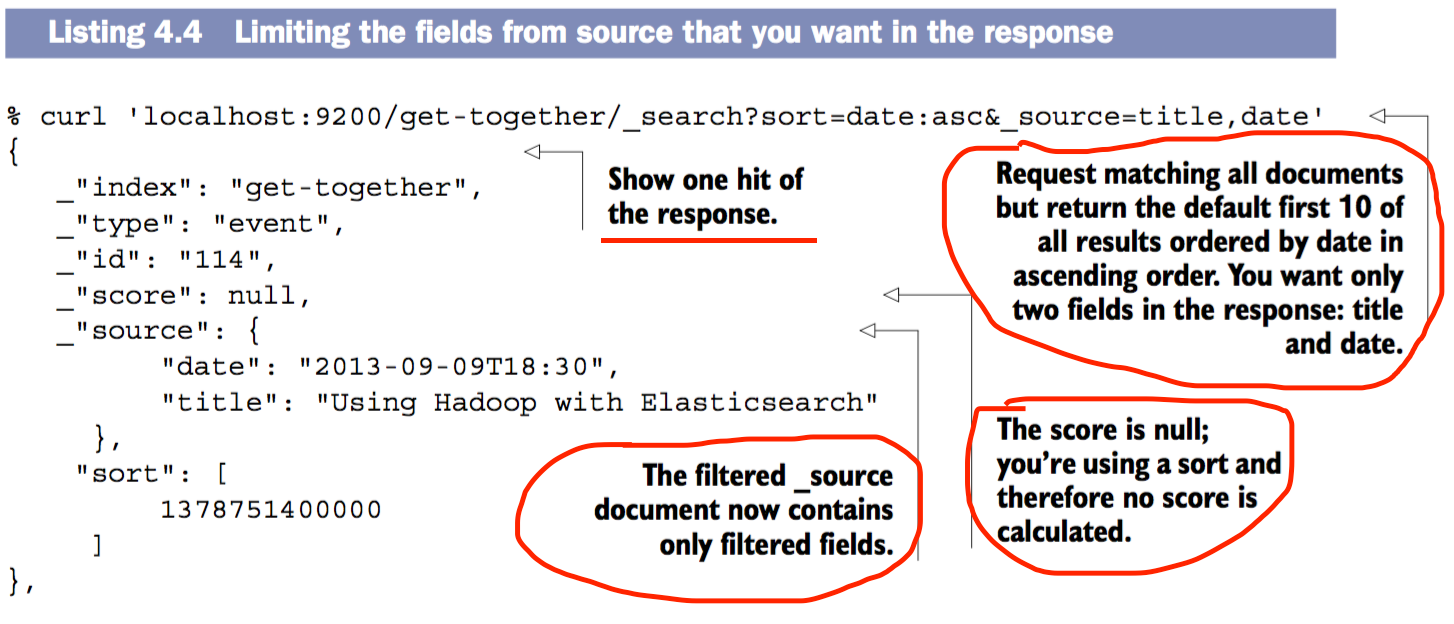
- Request matching all events with the word “elasticsearch” in their title
- 搜索所有title字段中包含
elasticsearch的结果,并按date的升序排列。
基于body的搜索请求
-
获取第二页的10个结果

-
指定返回结果中包含的字段

-
使用通配符指定返回结果中包含的字段

-
搜索结果多维度排序
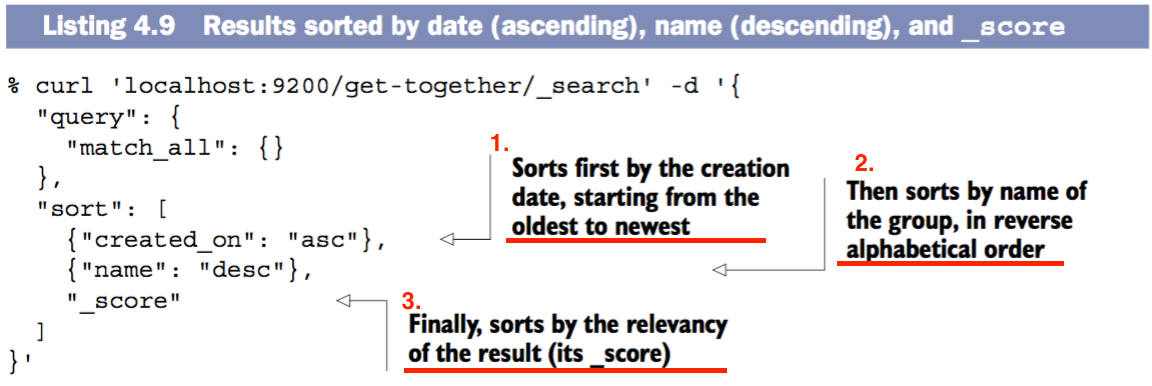
选取多值字段或可分词字段进行排序往往会带来一些问题(不知道选取哪一个值元素作为排序的指标),所以最好还是选用不可分词字段或者数值字段进行排序。
-
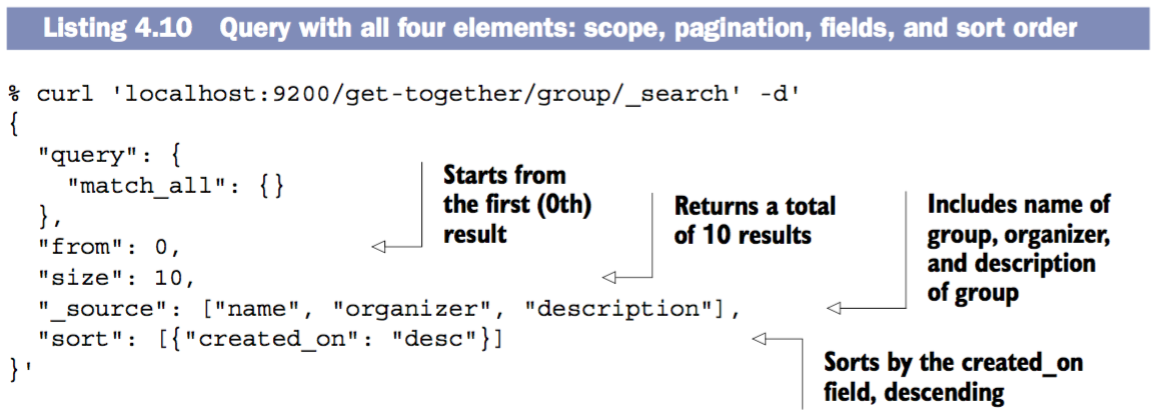
综合运用基本的请求参数
解析搜索结果


Query和filter DSL 简介

match query 和 term filter
-
matchquery 查找title字段中包含’Hadop’的文档
-
query 和 filter的主要区别
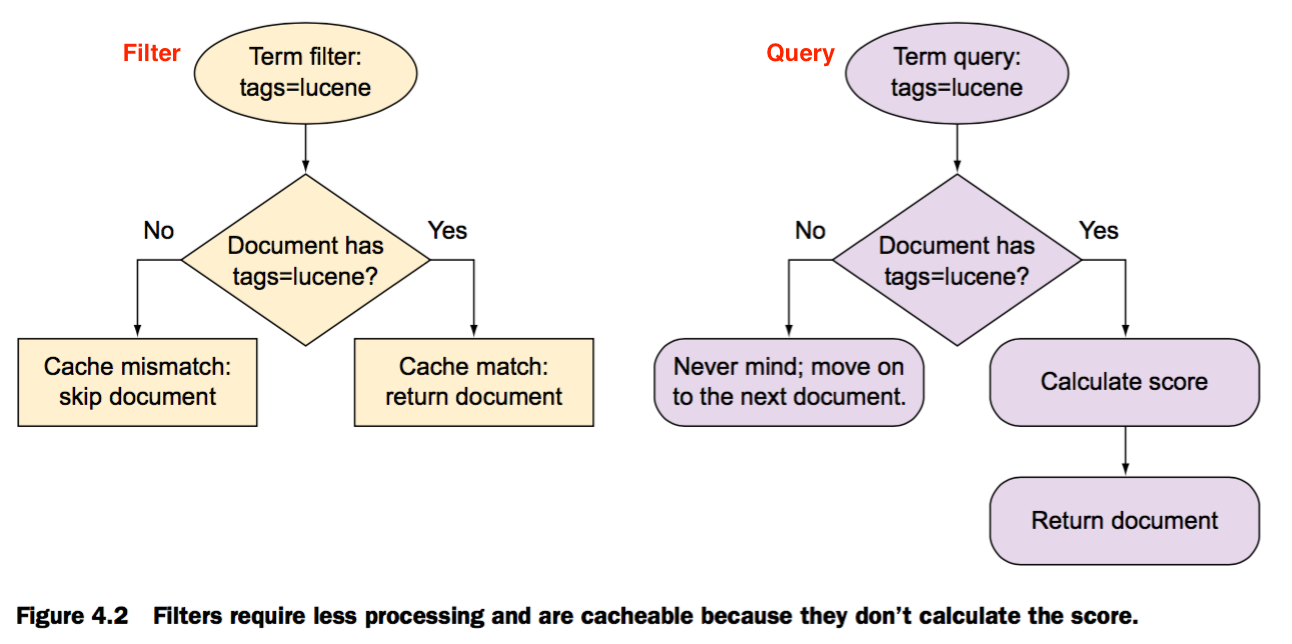 由于这些不同,filter的性能是优于一般的query的,并且filter还能被缓存。
由于这些不同,filter的性能是优于一般的query的,并且filter还能被缓存。 -
包含query和filter的filter查询
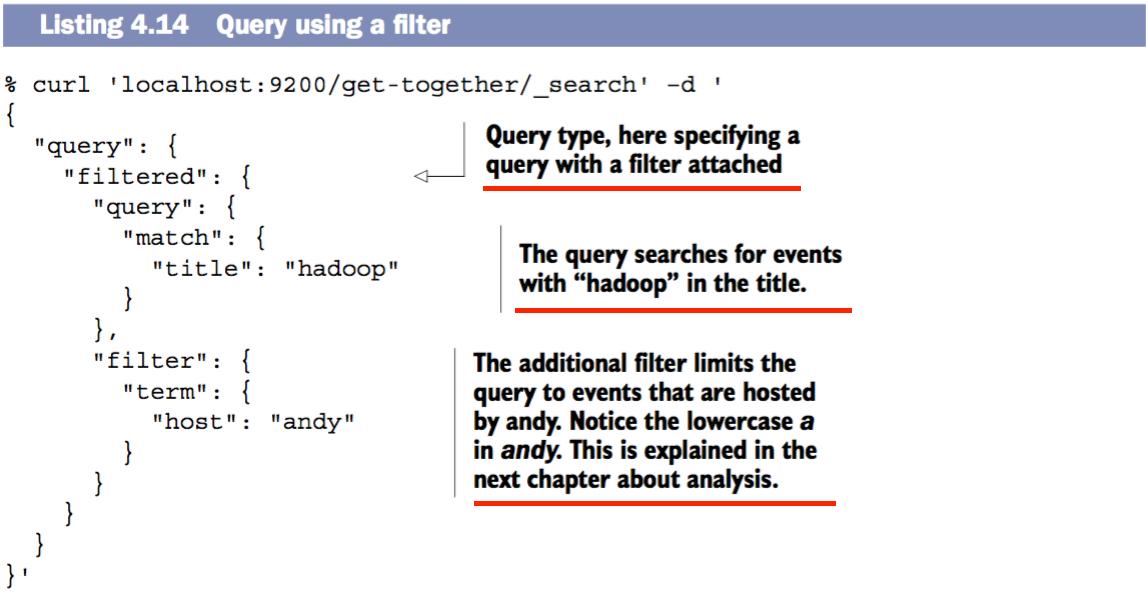
综合运用query和filter查询性能会优于单独使用query查询。原因是filter查询减少了query查询的一些不必要的运算,还有就是filter能被缓存从而进一步提高了性能。
常用的query和filter
-
match_allQuery 匹配所有文档$ curl 'localhost:9200/_search' -d ' { "query" : { "match_all" : {} } }' -
query_stringQuery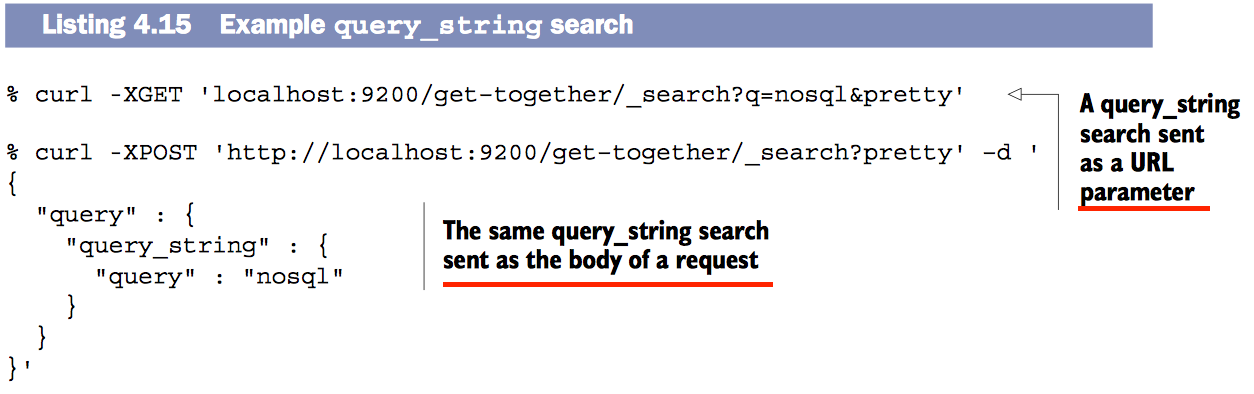 默认
默认query_string查询_all字段(即全部字段)。可以配置其查询指定字段或查询默认字段,例如description:nosql
query_string最大的坏处就是太强大,若不当使用将会给集群带来风险。使用时,建议使用term,terms,match,multi_match代替.另一个替代方案是使用简单查询语法如+, -, AND, OR -
term Query 和 term Filter 可以指定字段和term搜索文档。因为term被用于搜索是不能被分词的,必须精确匹配term才会有返回结果
使用term query 搜索tag中包含elasticsearch的文档
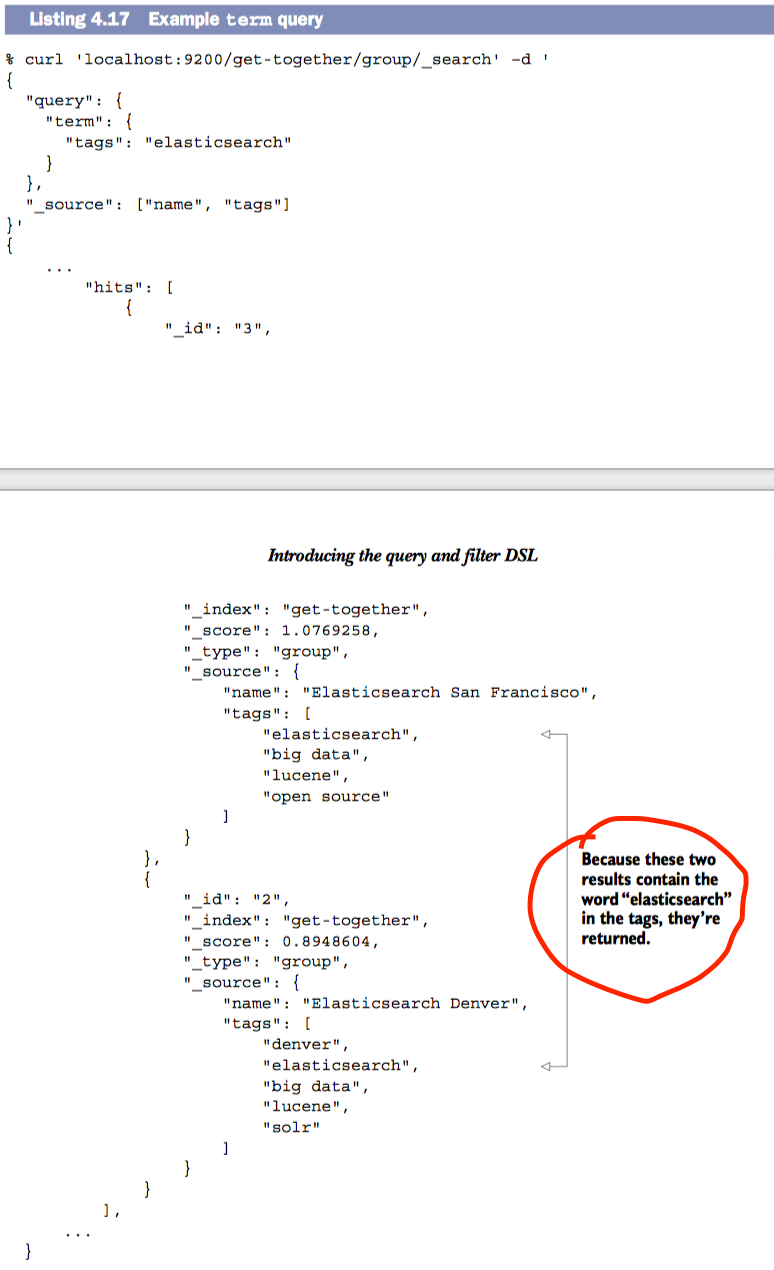 使用term filter时,不会运算score值
使用term filter时,不会运算score值
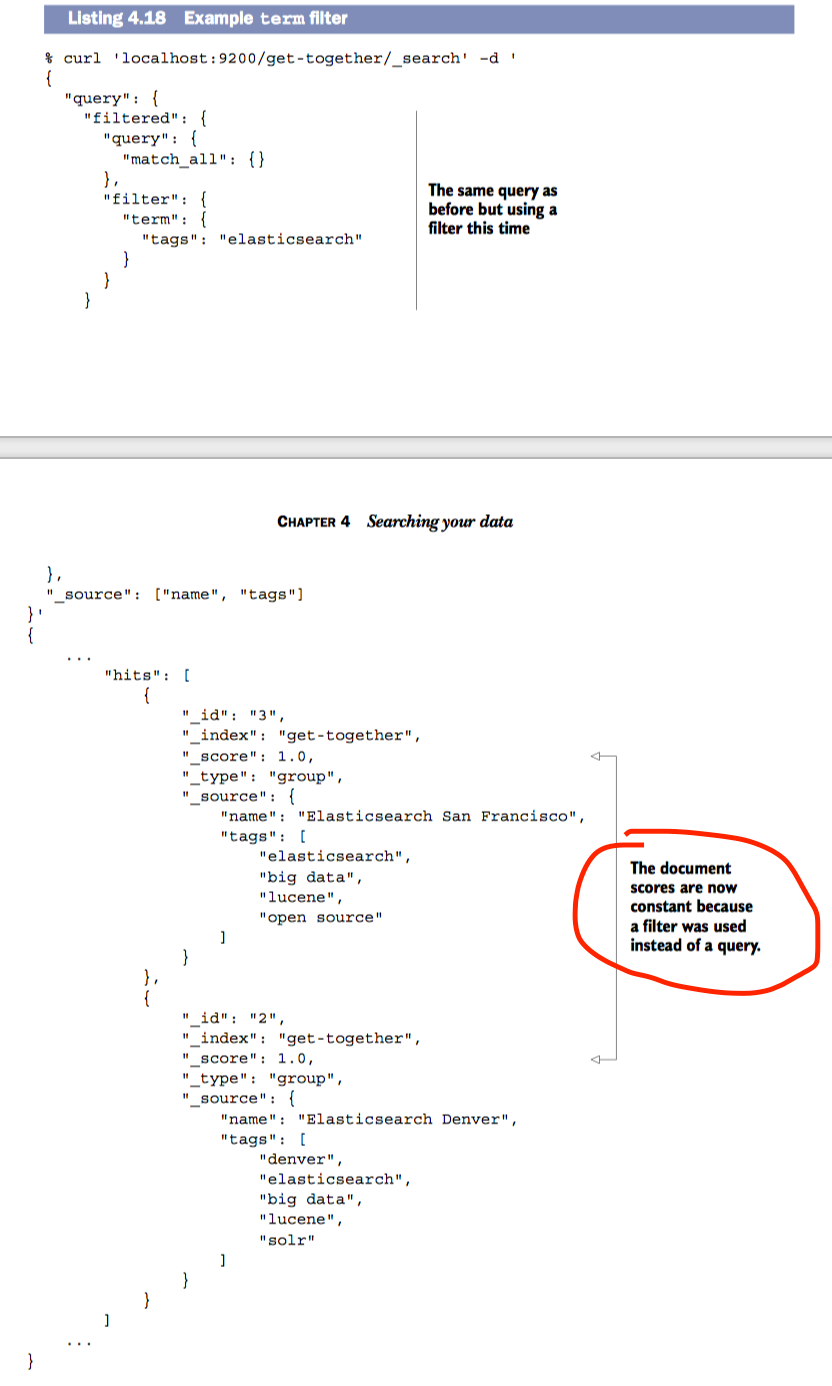
-
termsQuery 在文档字段中搜索多个term 例如:搜索tag是jvm或hadoop的文档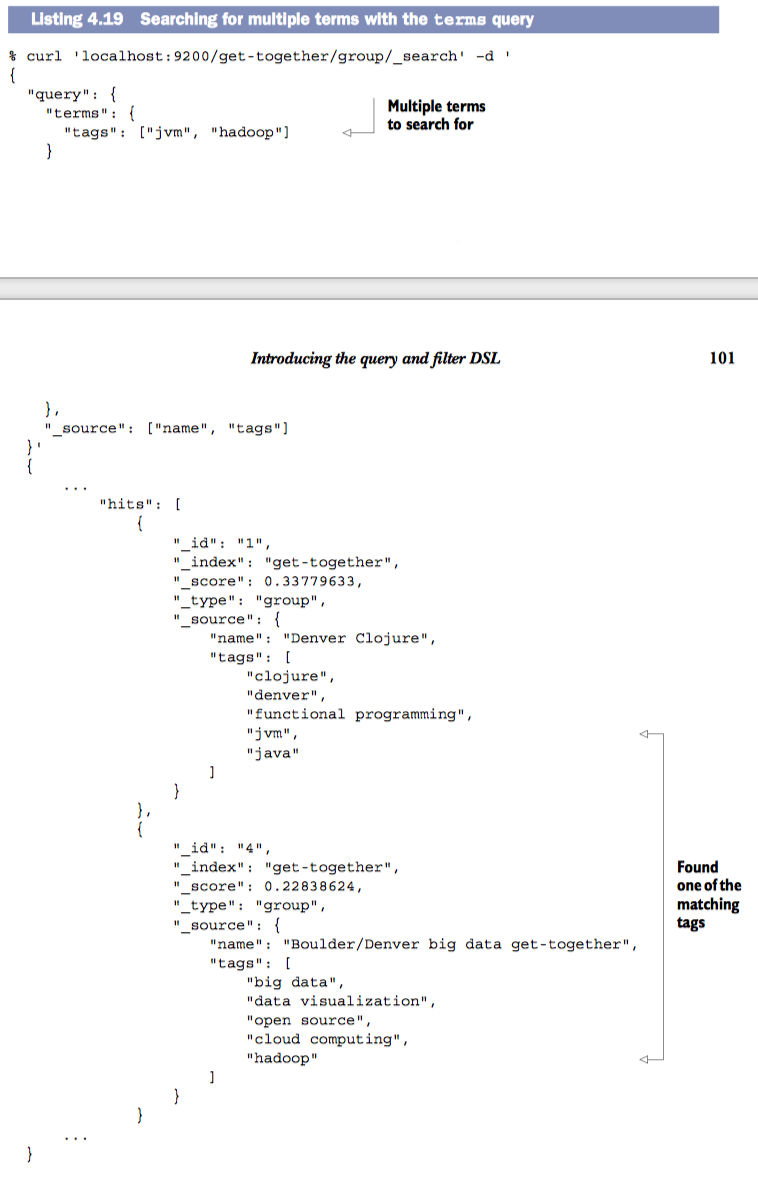
查询时设置最少匹配term的数量,配置参数
minimum_should_match$ curl 'localhost:9200/get-together/group/_search' -d '{ "query": { "terms": { "tags": ["jvm", "hadoop", "lucene"], "minimum_should_match": 2 } } }'
match query和term filter
match query的值是哈希键值对,键就是field,值就是你要查询的内容,可以一次针对一个字段查询,也可以一次对所有字段查询。
$ curl 'localhost:9200/get-together/group/_search' –d '{
"query": {
"match": {
"name": "elasticsearch"
}
}
}'
matchquery,有多个参数可以配置;最重要的是boolean和phrase
-
逻辑查询 默认
matchquery 使用逻辑查询的或操作符。例如,如果搜索文本:“Elasticsearch Denver”,Elasticsearch拆词后实际运行的是Elasticsearch OR Denver,匹配到的结果将是“Elasticsearch Amsterdam” 和 “Denver Clojure Group.” 示例:修改逻辑操作符为AND
-
短语查询 在文档中查询指定短语时,短语查询是很好用的.还可以设置短语单词之间模糊匹配的token数。例如只记得name中包含Enterprise和London,其他不记得是啥。那么可以使用短语查询,并设置slop参数为1或2,而不是默认的0.也就是说可以不用知道确切的文本也可以搜索

phrase_prefix query
match phrase_prefix可以实现一步到位的搜索。他可以匹配以phrase为前缀的字段内容
这个是非常有用的,可以实现搜索时自动完成的功能;可能一次返回大量结果,但是可以限制返回数量

-
使用
multi_match匹配多个字段multi_match可以实现跨多个字段的查询,在name和description中搜索文本$ curl 'localhost:9200/get-together/_search' -d' { "query": { "multi_match": { "query": "elasticsearch hadoop", "fields": [ "name", "description" ] } } }'
就像match query变成 phrase query, prefix query,或 phrase_prefix query, multi_match query也能变成phrase query 或者 phrase_prefix query.除了一个能指定多个字段一个只能指定一个字段,multi_match query和 match query很像
组合查询
bool query
bool query可以使用布尔关键字把多个查询组合成一个。这些关键字包括must, should, must_not
| 布尔查询关键字 | 等价逻辑 | 解释 |
|---|---|---|
| must | 使用函数and组合多个从句 (query1 AND query2 AND query3). | 任何在must子句中的搜索必须匹配文档。小写的and是函数,大写的AND是操作符. |
| must_not | 使用not组合多个子句 | 任何在must_not子句中的搜索必须排除匹配的文档。(NOT query1 AND NOT query2 AND NOT query3). |
| should | 使用or组合多个子句 | 在should子句中搜索,可匹配可不匹配文档, 但是至少应该匹配minimum_should_match参数设置的数量(must不存在默认是1,must存在默认是0)(query1 OR query2 OR query3). |
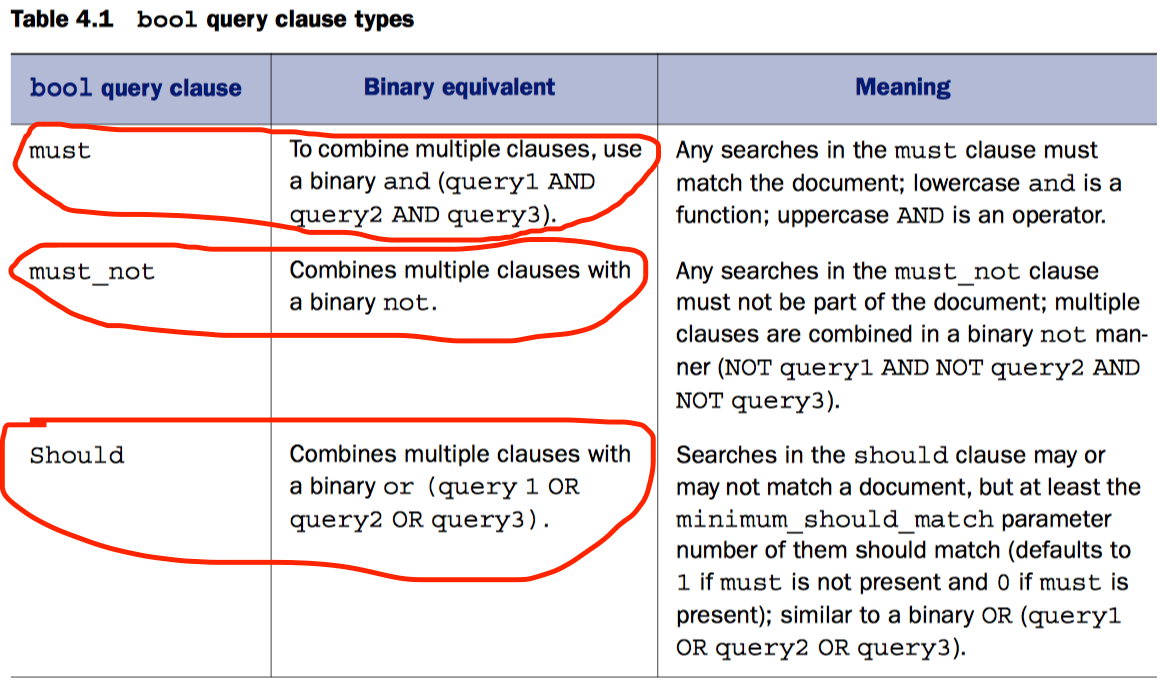
示例: 搜索文档:attendees是David, attendees是Clint 或 Andy,并且不能晚于2013-06-30

minimum_should_match 设定了必须匹配的should子句的数目
bool filter
用bool filter组合多个filter
$ curl 'localhost:9200/get-together/_search' -d'
{
"query": {
"filtered": {
"query": {
"match_all": {}
},
"filter": {
"bool": {
"must": [
{
"term": {
"attendees": "david"
}
}
],
"should": [
{
"term": {
"attendees": "clint"
}
},
{
"term": {
"attendees": "andy"
}
}
],
"must_not": [
{
"range" :{
"date": {
"lt": "2013-06-30T00:00"
}
}
}
]
}
}
}
}
}'
bool filter不支持minimum_should_match,should子句至少有一个匹配
改善BOOL QUERY
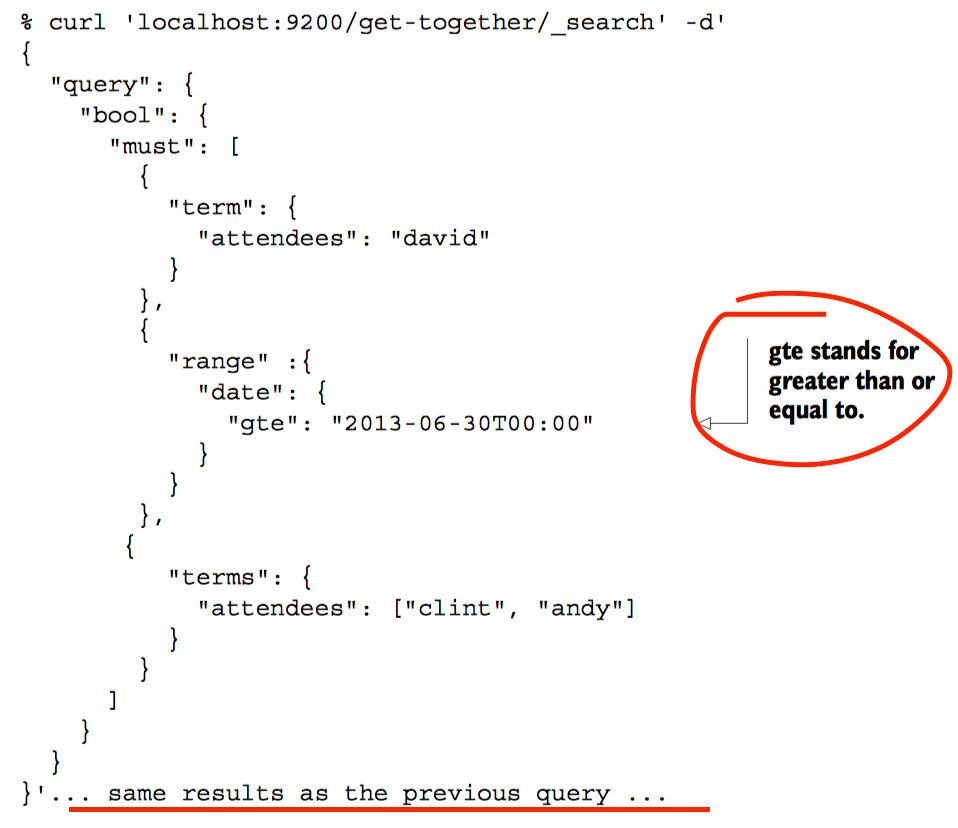
注 参数minimum_should_match对于默认值有一些隐藏的特性,使用must时默认值是0,没有must时默认值是1
除了match和filter查询
Range查询和过滤
其被用来在确定的范围内查询。数值,日期,甚至字符串都能使用。使用range查询,你要指定字段匹配的上下边界值
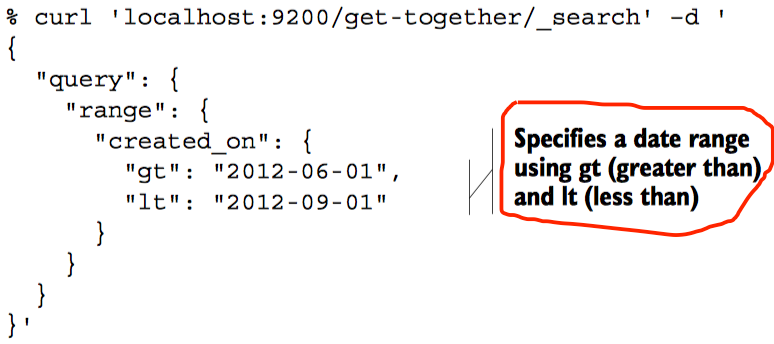 使用range过滤
使用range过滤
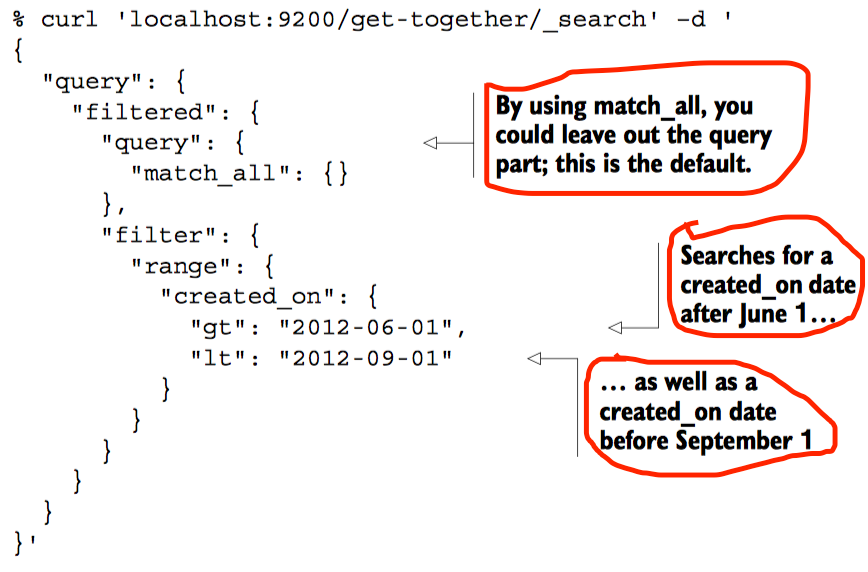
Range查询的参数

range查询支持字符串。例如查询name 在”c”和”e”之间的文档
$ curl 'localhost:9200/get-together/_search' –d '
{
"query":{
"range":{
"name":{
"gt": "c",
"lt": "e"
}
}
}
}
老生常谈,基于性能的考虑应当优先使用filter.在不确定使用query还是filter时,99%使用filter是正确的选择
Prefix 查询和过滤
Prefix 查询和过滤可以搜索包含给定前缀的term,这个前缀在搜索前是不被分词的
这就意味着 查询’liber’和查询’Liber’将得到不同的结果.因为前缀在搜索前是不会做分词处理的,所以不会找到index中小写的内容
例如:搜索title前缀为liber的文档
$ curl 'localhost:9200/get-together/event/_search' –d '
{
"query": {
"prefix": {
"title": "liber"
}
}
}'
使用filter的方式搜索
$ curl 'localhost:9200/get-together/event/_search' –d '
{
"query": {
"filtered": {
"query": {
"match_all": {}
},
"filter": {
"prefix": {
"title": "liber"
}
}
}
}
}'
通配符查询
Elasticsearch支持*通配符代替任意数量的字符(包括none),也支持?通配符代替单个字符。
示例:
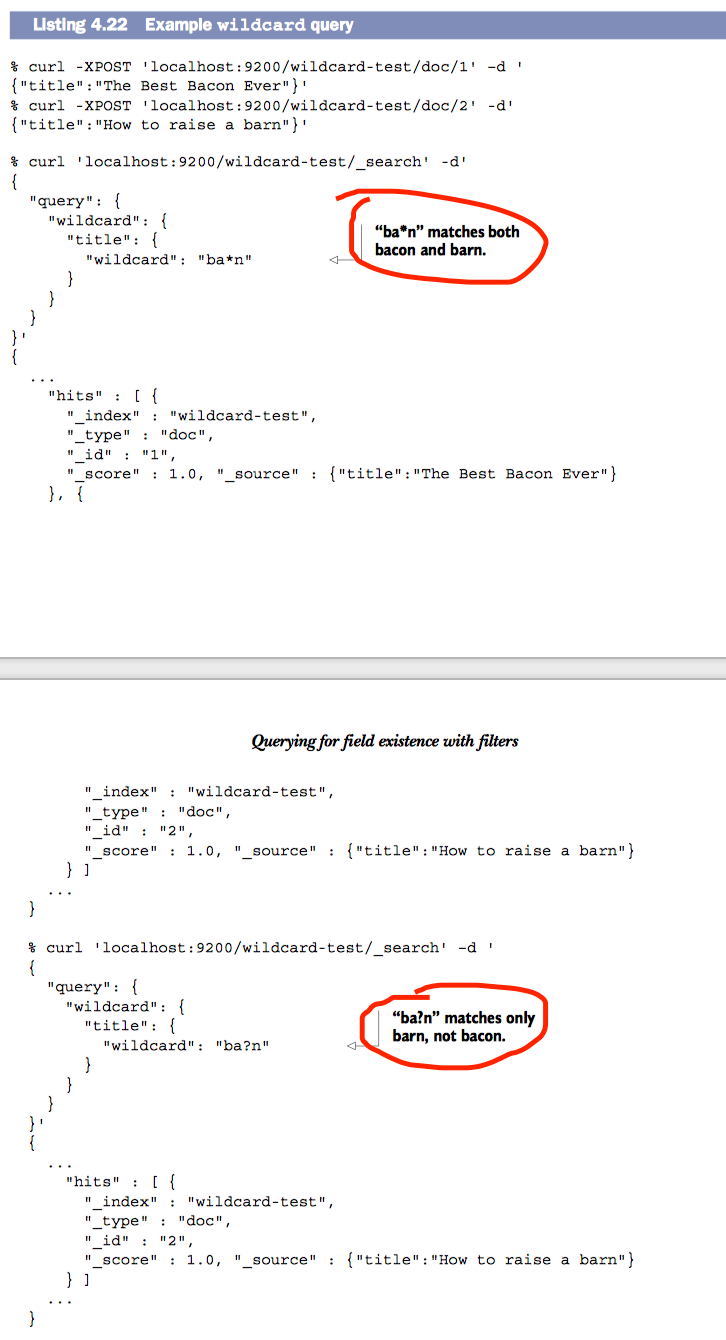
使用filter查询字段是否存在
Exists filter
示例:只返回包含字段location.geolocation的文档
$ curl 'localhost:9200/get-together/_search' –d '
{
"query": {
"filtered": {
"query": {
"match_all": {}
},
"filter": {
"exists": {
"field": "location.geolocation"
}
}
}
}
}'
Missing filter
missing filter 可以过滤没值或者null值的字段
示例:搜索reviews字段没有值的文档

想进一步过滤某个字段是否是null_value字段.可以指定布尔参数existence和`null_value
示例:查询review字段是null_value的文档

missing和exists filter默认是被缓存了的
转换任意的query成为filter
转换query_string query成为filter,例如:搜索name匹配“denver clojure”的文档
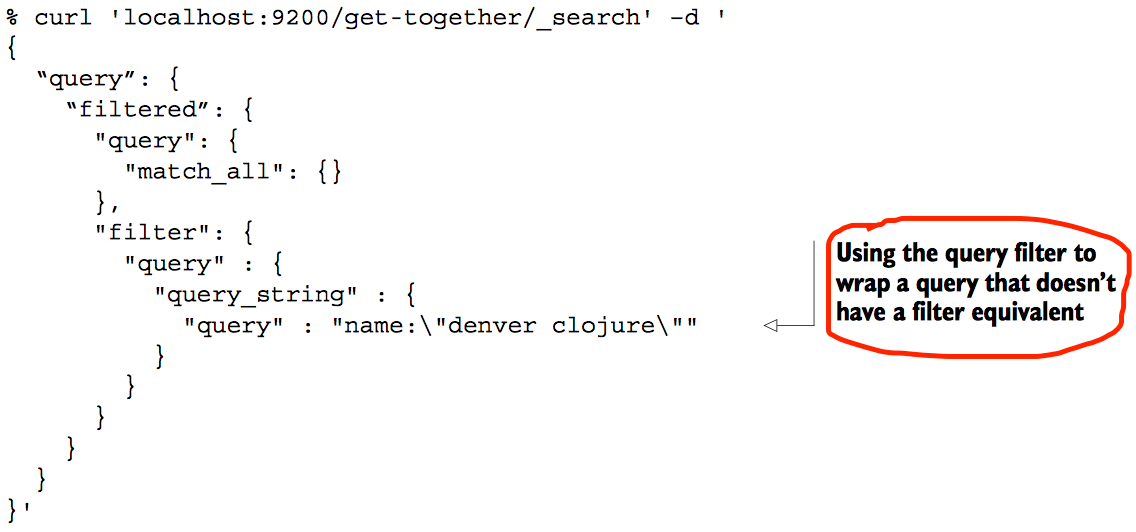
当某个filter使用很频繁时可以选择将其缓存

选择最佳的query
| 用例描述 | 使用的query类型 |
|---|---|
| 利用用户输入实现google风格的搜索 | 若要支持+/-和指定字段搜索那么请使用match query 或者 simple_query_string query |
| 将用户输入作为短语并允许若干容错 | 使用match_phrase query并配置参数slop执行搜索 |
| 在不可分词字段搜索单个词,并确定其是否出现 | 使用term query因为查询 terms是不分词的 |
| 用一个查询组合多个不同的查询 | 使用bool query组合任意数量的子查询 |
| 跨字段搜索确定的词句 | 使用multi_match query,其和match query用法很相近只是用于多字段 |
| 一次搜索返回所有文档 | 使用match_all query |
| 搜索一个值在指定范围内的字段 | 使用range query |
| 搜索一个值以指定字符串开始的字段 | 使用prefix query |
| 基于用户输入自动完成 | 使用 prefix query 发送用户输入并返回以用户输入开始的精确匹配结果 |
| 搜索所有特定字段没有值的文档 | 使用missing filter |
总结
filter可以加速查询,因为其跳过了score计算并还有缓存
- 自然语音搜索,像match和query_string查询,适合用于搜索框
- match query 是全文搜索,query_string query更灵活,更复杂,因为它暴露了全部的Lucene查询语法
- match查询有多个子类型:boolean, phrase, and phrase_prefix。主要的不同是boolean匹配独立的字符串,phrase需要配置slop参数确定模糊搜索程度
- 也支持前缀查询和通配符查询
- 使用missing filter过滤字段不存在的文档.
- exists filter 真好相反,返回指定字段值的文档。