使用cUrl索引文档
索引文档
curl -XPUT 'localhost:9200/get-together/group/1?pretty' -d '{
"name": "Elasticsearch Denver",
"organizer": "Lee"
}'
复制上面代码到sense并执行显示效果如下图所示:
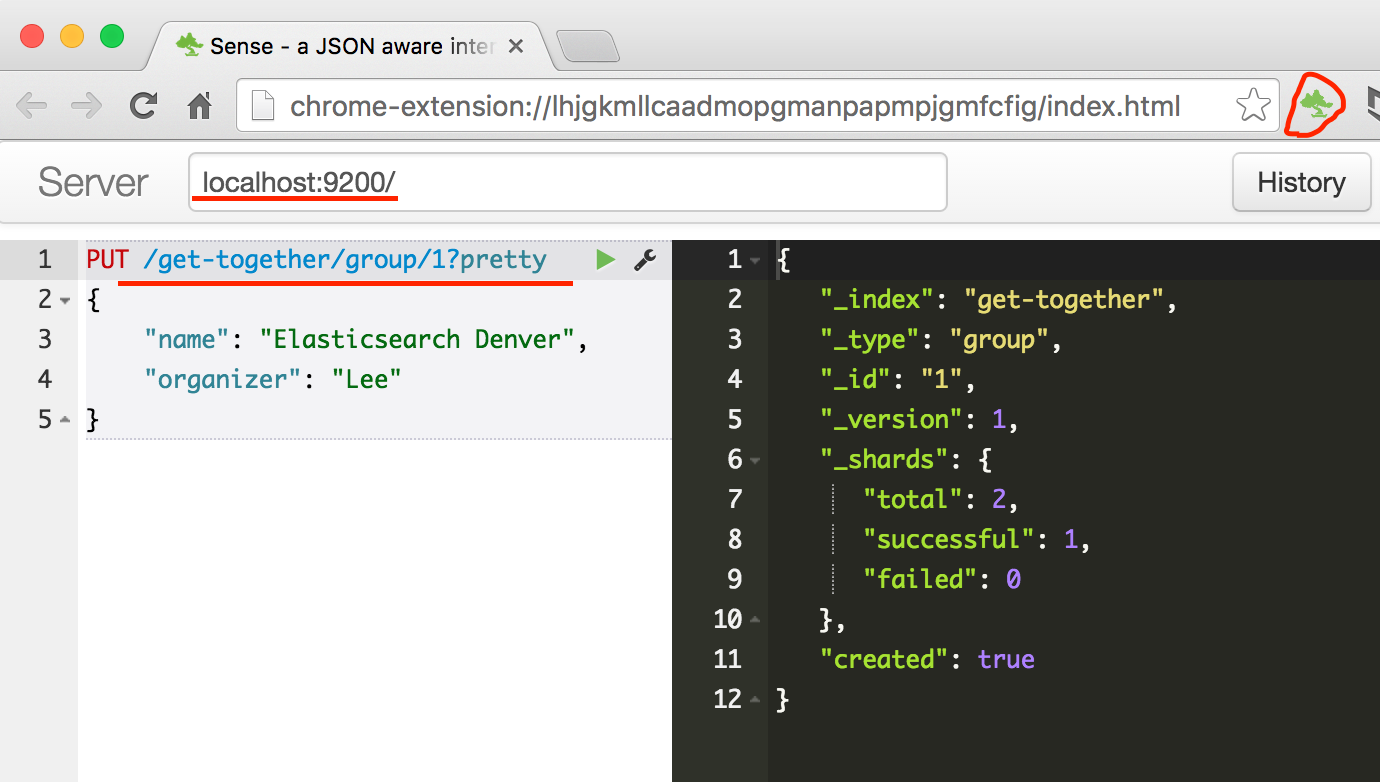
注: pretty参数在sense中是不必要的。其curl时起作用,使输出结果可读。
获取index中指定type的mapping
用关系型数据库的概念理解就是获取数据库中指定table的schema
如下图所示index是get-together,type是group
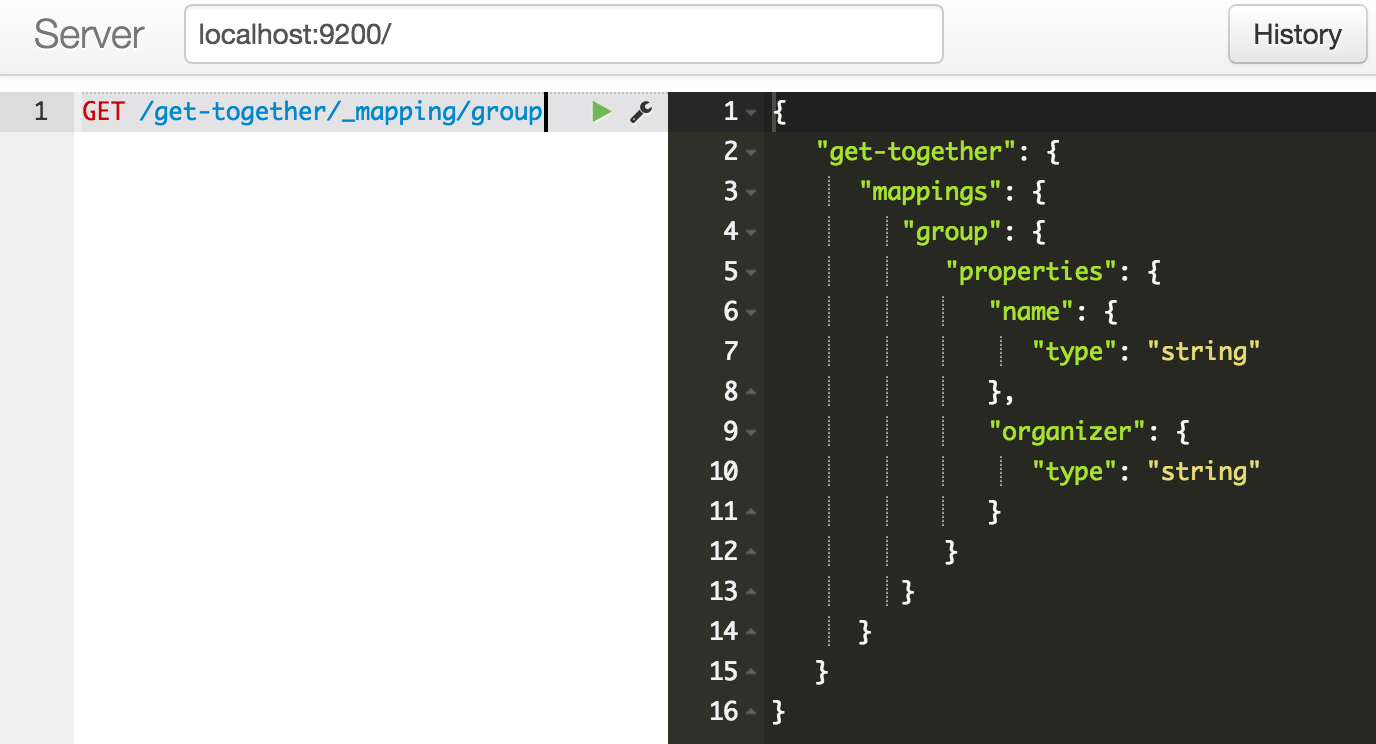
示例数据
https://github.com/dakrone/elasticsearch-in-action.git
使用脚本完成数据索引
$ ./populate.sh
搜索和读取数据
在哪里搜索
你可以使用Elasticsearch搜索指定index的指定type,你也能搜索 相同/多个/全部index的多个type
-
在多个type中搜索,type之间使用
,作为分隔符$ curl "localhost:9200/get-together/group,event/_search?q=elasticsearch&pretty" -
在全部type中搜索
$ curl 'localhost:9200/get-together/_search?q=sample&pretty' -
在多个index中搜索,同样index之间使用
,作为分隔符$ curl "localhost:9200/get-together,other-index/_search?q=elasticsearch&pretty" -
在全部index中搜索 搜索全部index使用
_all作为index名称,例如,你要搜索全部index中type为event的数据$ curl "localhost:9200/_all/event/_search?q=eeee"
异常情况
使用curl 'localhost:9200/_search?q=elasticsearch&pretty'执行搜索会报错;如果要在输出结果中忽略错误,添加参数ignore_unavailable即可,用法和pretty相同
搜索结果解析

- 时间
took字段显示请求消耗的时间,单位是毫秒.-
timed_out字段表示搜索是否超时 默认情况下搜索不会超时. 当然你可以设定timeout的值,如果搜索超时timed_out将显示为truecurl "localhost:9200/get-together/group/_search\ ?q=elasticsearch\ &pretty\ &timeout=3s"
-
命中结果统计 默认
score是根据TF-IDF算法计算而来。(TF-IDF: term frequency-inverse document frequency) 默认只返回10条搜索解构,可以设置参数size自定义返回结果的数目. - 返回结果
搜索指定字段,例如
q=name:elasticsearch
使用source filtering 自定义哪些原始数据中的field在返回结果中显示,详见:www.elastic.co/guide/ en/elasticsearch/reference/master/search-request-source-filtering.html
怎样搜索
根据关键词elasticsearch查询
$ curl 'localhost:9200/get-together/group/_search?pretty' -d '{
"query": {
"query_string": {
"query": "elasticsearch"
}
}
}'
-
配置query_string 搜索“elasticsearch san francisco”时,默认会搜索所用字段,假如你要搜索特定字段比如name,可以做如下设定
"default_field": "name"搜索结果默认返回所有匹配到的结果,即使是匹配到一个词(默认的operator是
OR)。如果要完整匹配搜索的语句,可以做如下设定。"default_operator": "AND"下面是完整的curl 查询代码:
$ curl 'localhost:9200/get-together/group/_search?pretty' -d '{ "query": { "query_string": { "query": "elasticsearch san francisco", "default_field": "name", "default_operator": "AND" } } }'另一种方式就是直接构建一个查询字符串:
"query": "name:elasticsearch AND name:san AND name:francisco"这个功能是从Lucene继承的
-
选择正确的查询类型 假如你在name字段中查询关键字“elasticsearch”,那么使用term类型的查询将即简单又高效
$ curl 'localhost:9200/get-together/group/_search?pretty' -d '{ "query": { "term": { "name": "elasticsearch" } } }' -
使用Filter Filter只关注关键字是否匹配搜索结果。
$ curl 'localhost:9200/get-together/group/_search?pretty' -d '{ "query": { "filtered": { "filter": { "term": { "name": "elasticsearch" } } } } }'返回结果和使用term查询语句返回的结果是一致的,但是filter的返回结果不会按score排序(因为score的分数都是1.0)
-
应用AGGREGATIONS 使用
terms聚合函数返回organizer$ curl localhost:9200/get-together/group/_search?pretty -d '{ "aggregations" : { "organizers" : { "terms" : { "field" : "organizer" } } } }'如下所示,返回每个关键字在指定filed的文档中出现的次数
"aggregations" : { "organizers" : { "buckets" : [ { "key" : "lee", "doc_count" : 2 }, { "key" : "andy", "doc_count" : 1 ....
通过ID获取文档
返回结果如果存在,你会看到
found为true,以及相关信息。如果文档不存在那么found为false